Transport Layer#
Transport Layer Service#
Process 之間的 Communication (Host 之間 communication 是 network layer 的工作)
- Multiplexing & Demultiplexing
- Reliable transfer
- Flow control
- Congestion control
- UDP or TCP
Transport Layer action#
- Sender: 把 Application Layer message 封裝,加上 Transport layer header,往下送到 IP
Transport Layer action 1
- Receiver: Check header value,然後 Demultiplex message 到正確的 process
Transport Layer action 2
- TCP: Transmission Control Protocol
- UDP: User Datagram Protocol
- 不提供 Delay guarantee, Bandwidth guarantee
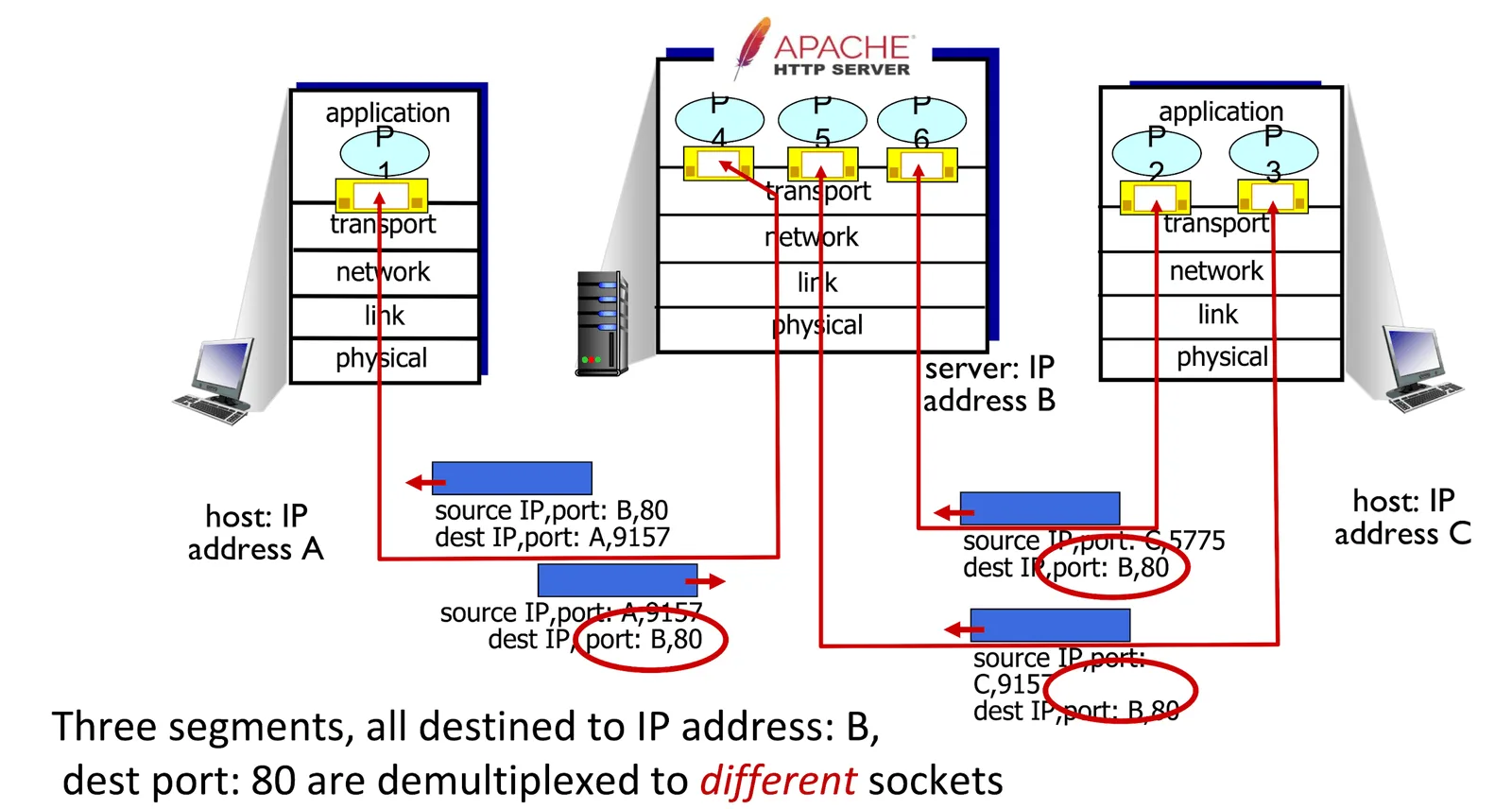
Multiplexing & Demultiplexing#
- 一台主機可能要接收很多 request,為了分別他們,將 response send 到正確的 client process 上,我們的可以使用 Multiplexing & Demultiplexing
- Multiplexing: 加上 header 幫助辨認傳送的地方
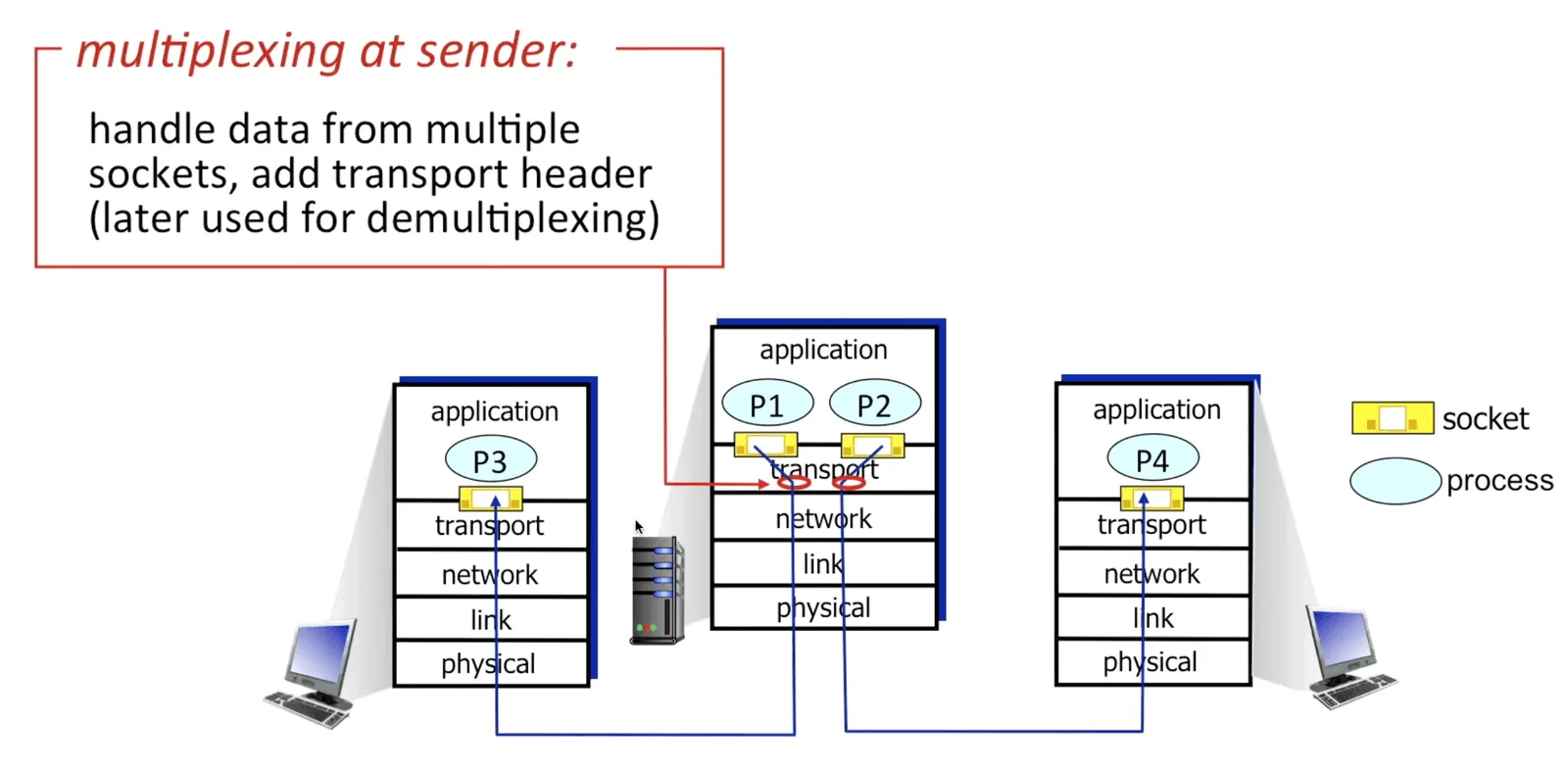
Multiplexing & Demultiplexing 1
- demultiplexing: 解讀 header 傳送到正確的 socket
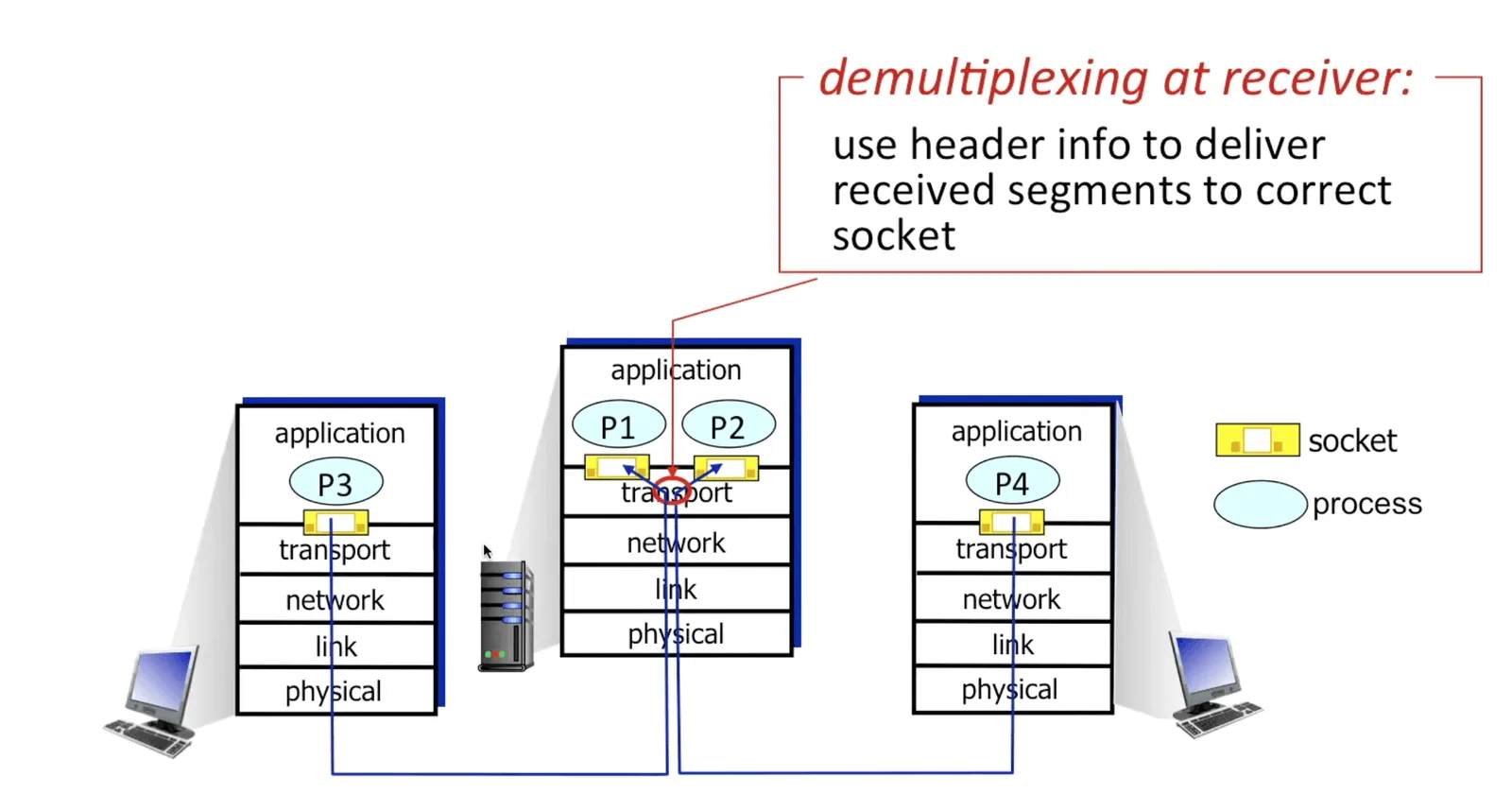
Multiplexing & Demultiplexing 2
Multiplexing & Demultiplexing for UDP#
- header 的架構必須有這些東西
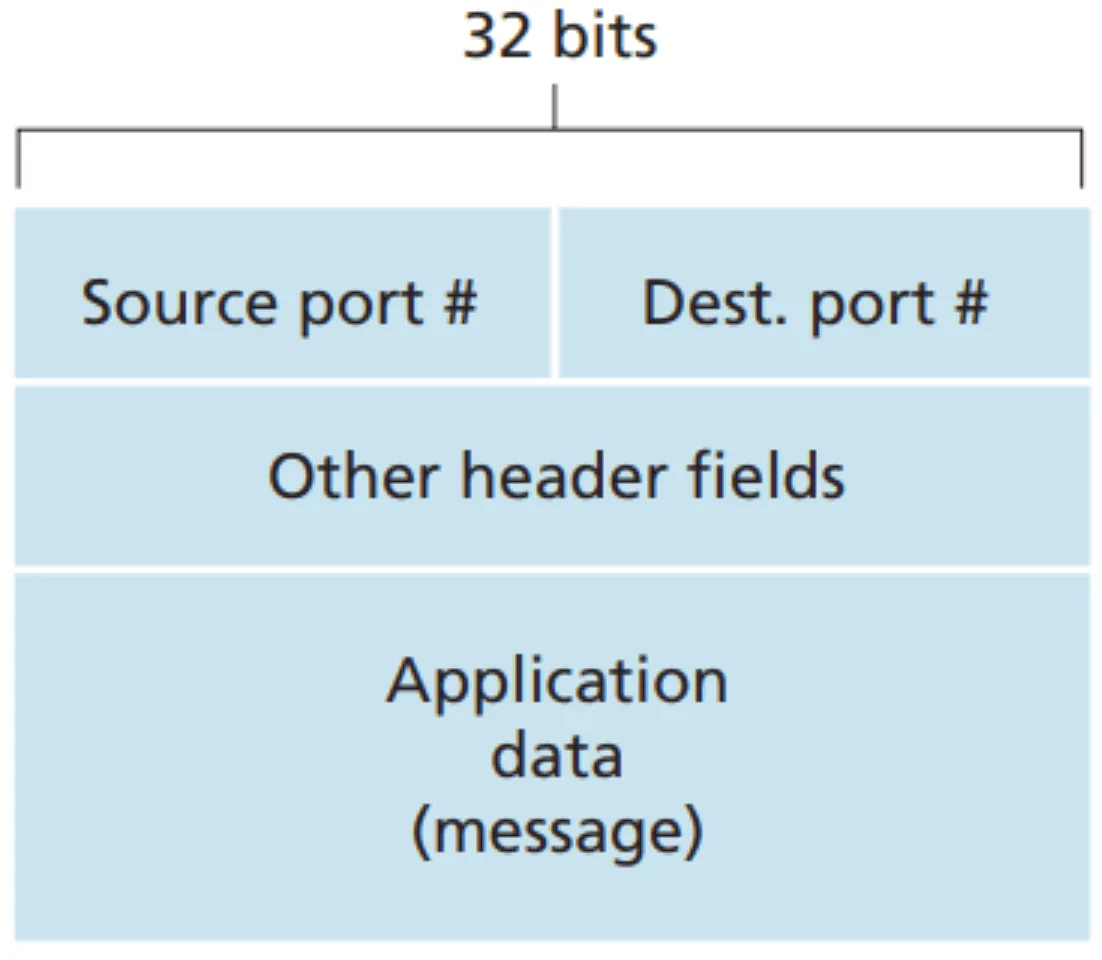
Multiplexing & Demultiplexing for UDP 1
- 機制如下
- Request 跟 Response 只需要交換 Source port, Destination port 就好了
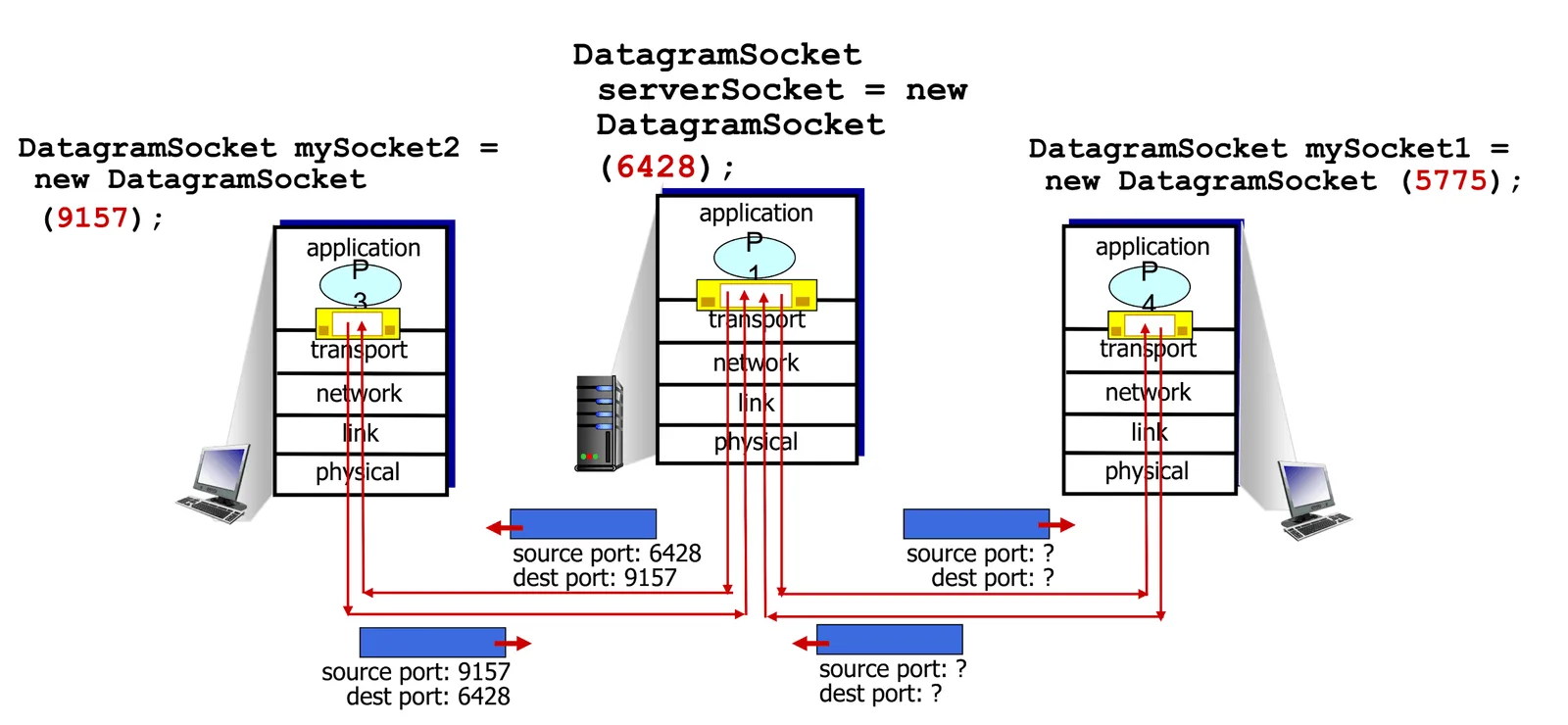
Multiplexing & Demultiplexing for UDP 2
Multiplexing & Demultiplexing for TCP#
- 稱為 Connection-oriented demultiplexing
- 用一個 4-tuple 紀錄 demultiplexing 資訊
- Source IP address
- Source port number
- Destination IP address
- Destination port number
- 即便是同一個 port 還是會被開到不同的 socket 裡面
- 一樣交換兩端資訊即可送回
Multiplexing & Demultiplexing for TCP
UDP (User Datagrams Protocol)#
- Connectionless 不需要 handshake
Use of UDP#
發現其實 Reliable transfer 不一定要建立在 Transport Layer 也可以放在 Application Layer
- DNS
- HTTP/3
- streaming multimedia (loss tolerent)
- SNMP
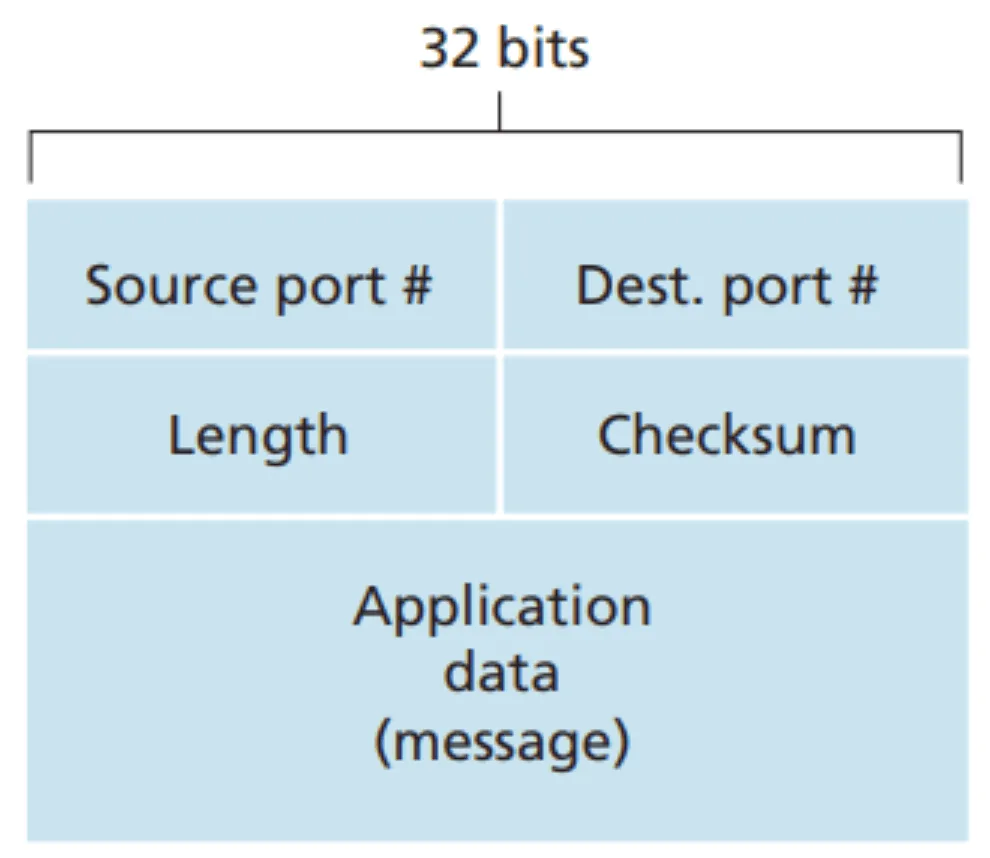
UDP structure#
- Source port, Dest. port
- Length: include header
- Checksum
UDP structure
UDP Check Sum#
- 檢查錯誤:像是 flipped bits,加起來不一樣就知道有 error
- Sender 會 把
header + message變成一串 16-bits 的 integer- 用 one’s complement 計算 Checksum
- Receiver 要計算 Checksum 看看是否有相悖。
- 不一樣:必定 error
- 一樣:還是可能有錯
Reliable Data Transfer (RDT)#
我們想像中是左圖,但實際上是右邊,並沒有真正的 reliable channel
Reliable Data Transfer 1
- 要考慮非常複雜的狀況,要站在另外一端的角度思考會發生什麼事情
- 要設計出一對這樣的 protocol 而且要可以雙向溝通
- 實際上的 interface 其實長這樣
Reliable Data Transfer 2
- 我們後面都用這種形式來表示狀態轉移
Reliable Data Transfer 3
rdt 1.0: Reliable transfer with Reliable channel#
- No bits error
- No loss packet.
- Sender 只要寄出,就回到原始狀態
- Receiver 只要接收後讀取,就回到原始狀態
rdt 1.0: Reliable transfer with Reliable channel
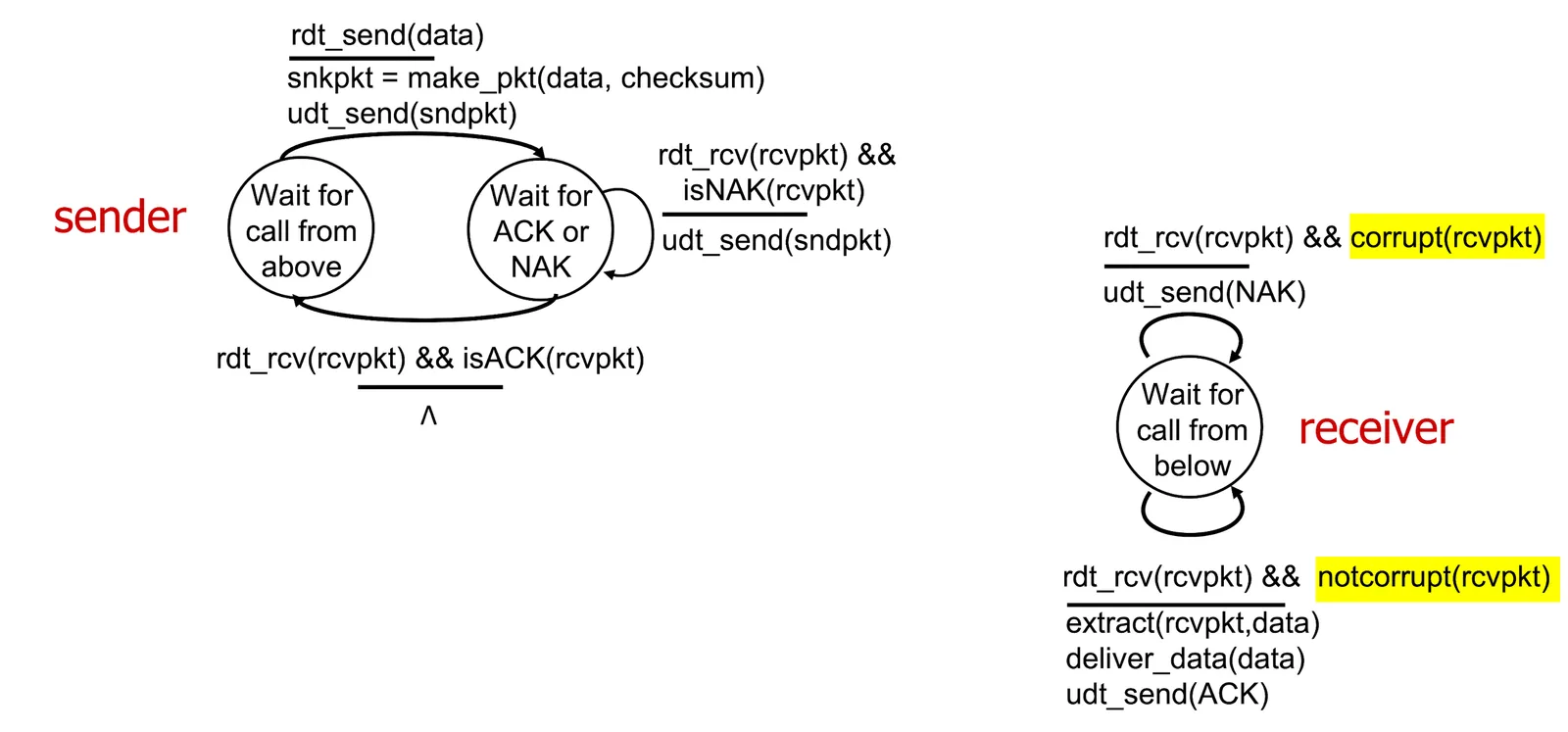
rdt 2.0: Channel with bits error#
- Maybe flipped bits
- To recover error 我們引入
- Acknowledgements(ACKs): 告訴 sender packet 可以
- Negative Acknowledgements(NAKs): 告訴 sender packet 不過
- Sender 收到 NAKs 後 retransmit
- 上述過程可以畫成這個 FSM
rdt 2.0: Channel with bits error
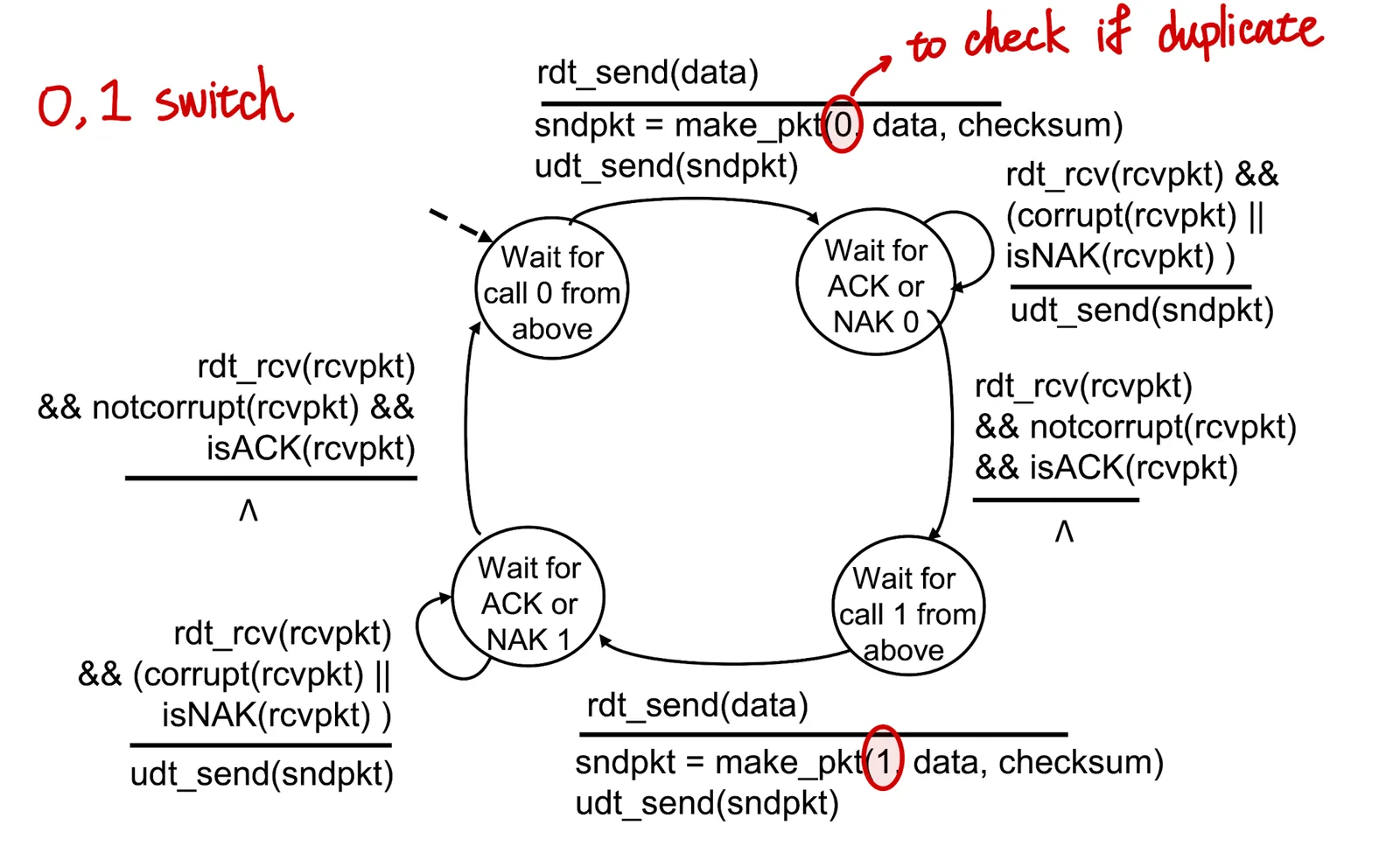
rdt 2.1: Handling Garble ACKs/NAKs#
- 如果 Receiver 送出的 ACKs/NAKs 是亂碼,那 Sender 就必須重複送一次資料我們稱為 duplicate
- 但 Receiver 並不知道自己寄出的是亂碼,所以需要讓 Sender 做一些事情讓 Receiver 知道這個 packet 是不是 duplicated 的
- 此時 Sender 必須 handle 一份 sequence of number 來讓對方知道這是不是 duplicated 的
- Sender:
- 在送出 packet 後,跟前者一樣,但當
corrupt()時要在原地等待 - 在
make_pkt()的時候要送 sequence 進去(0, 1)
- 在送出 packet 後,跟前者一樣,但當
rdt 2.1: Handling Garble ACKs/NAKs 1
- Receiver:
- 當收到並非自己 sequence number 的時候,也要在原地等待,並且送出
ACKs的資訊 - 要檢查是否是自己的 sequence number
- 當收到並非自己 sequence number 的時候,也要在原地等待,並且送出
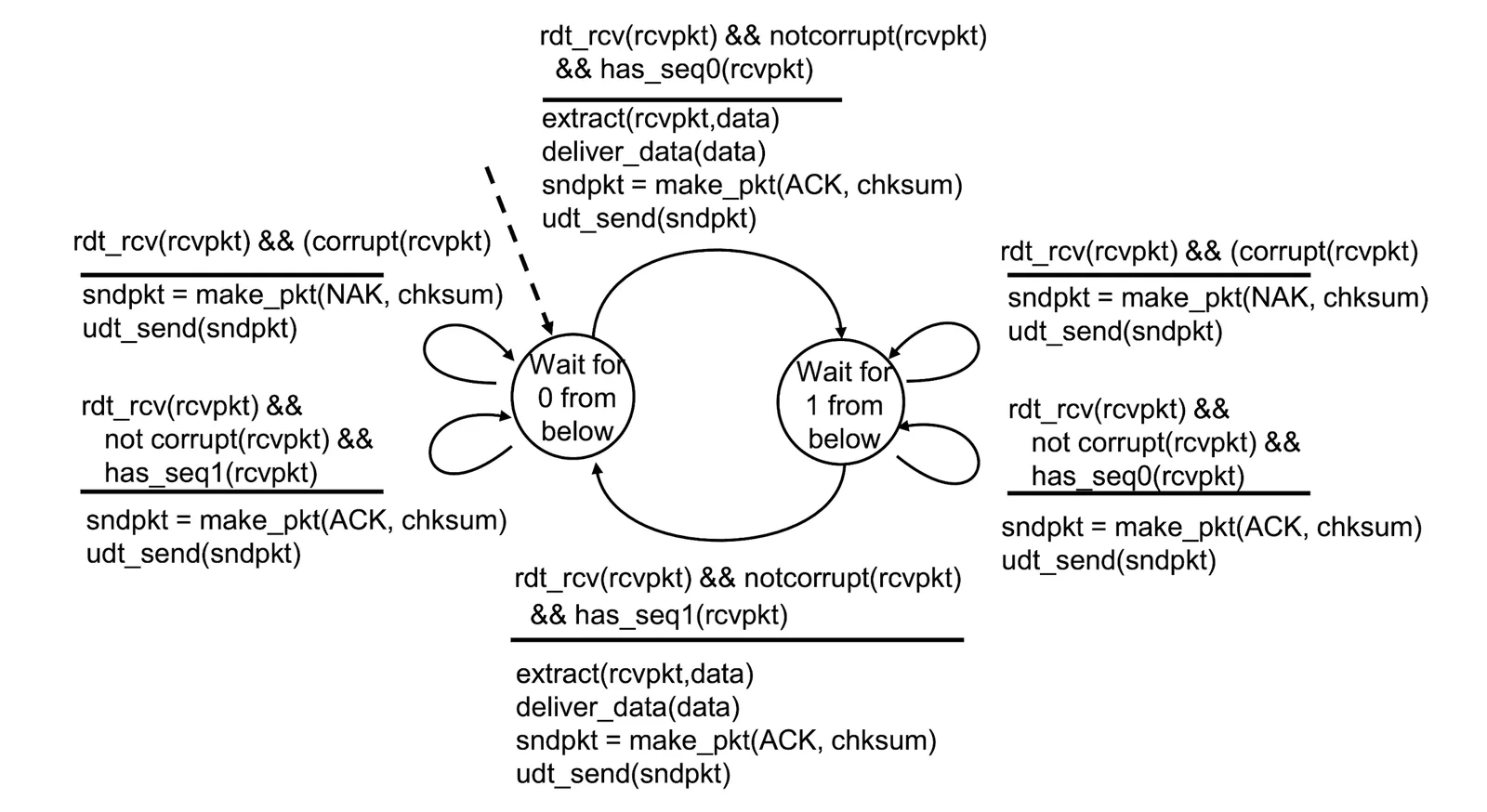
rdt 2.1: Handling Garble ACKs/NAKs 2
rdt 2.2: Free NAKs Protocol#
- 其實
NAK可以用udt_send()非自己 sequence number 來取代 - 可以簡化 FSM 成
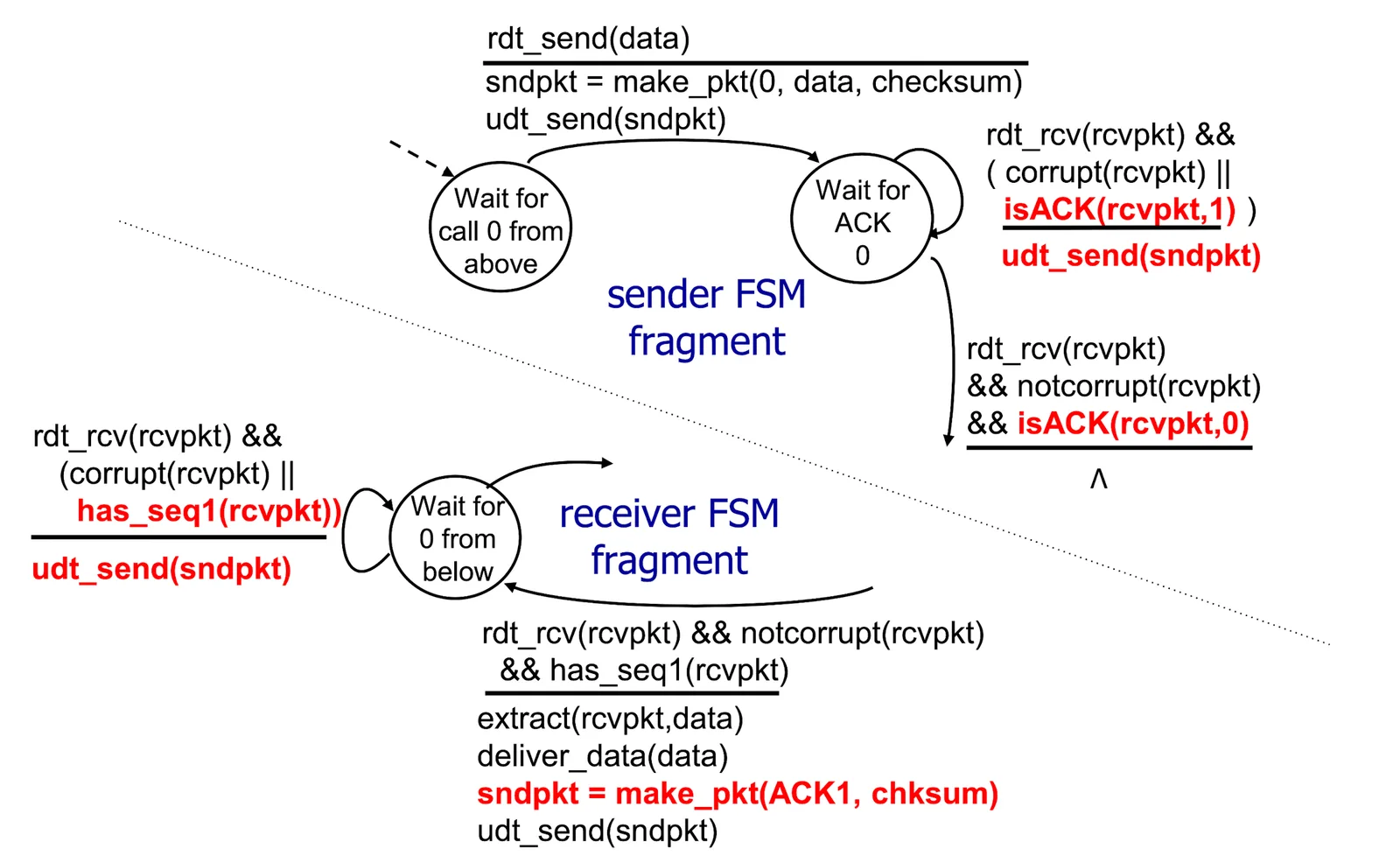
rdt 2.2: Free NAKs Protocol
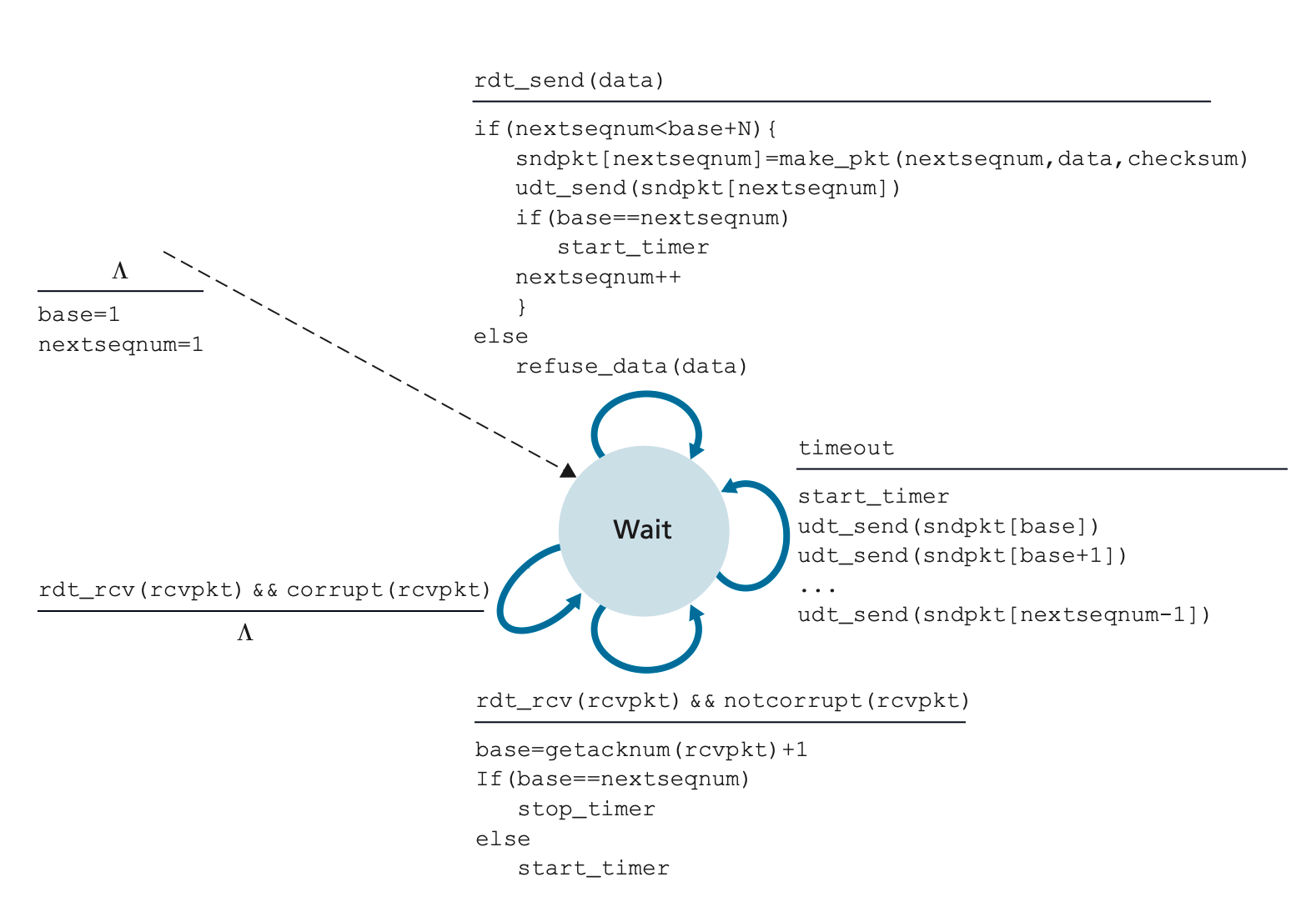
rdt 3.0 channels with errors and loss#
- 需要 resend 丟失的 packet
- pkt 可能會 delay (不是 lost)
- retransmission 可能會導致 duplicate packet 但是 sequence number 就可以 handle 了
- 要有 timeout checker 來檢查是否超過時間,超過則重新發送 pkt
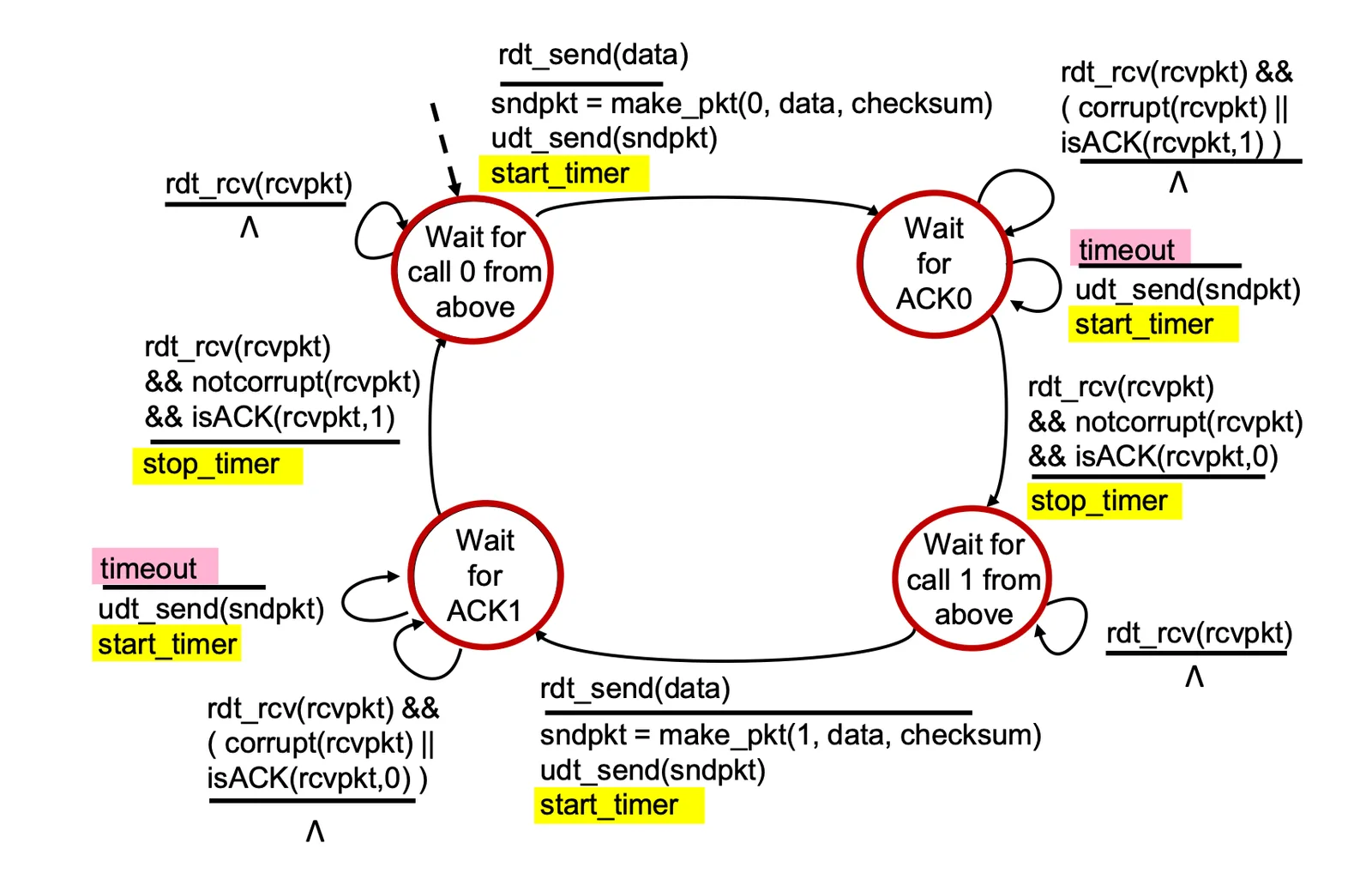
rdt 3.0 channels with errors and loss
star_timer於發送 pkt 開始計算stop_timer於is_ACK()發送
Action of rdt 3.0#
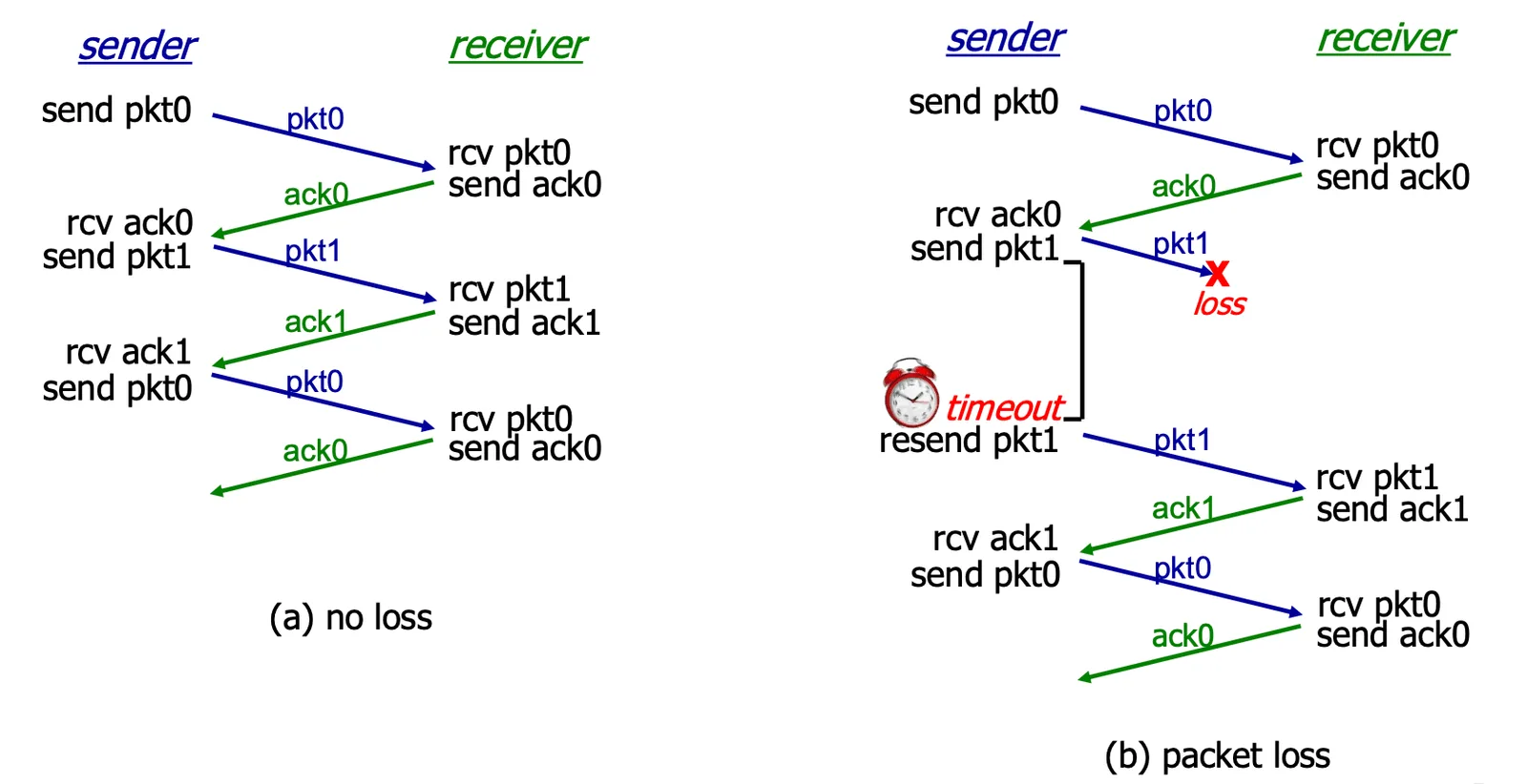
Action of rdt 3.0 1
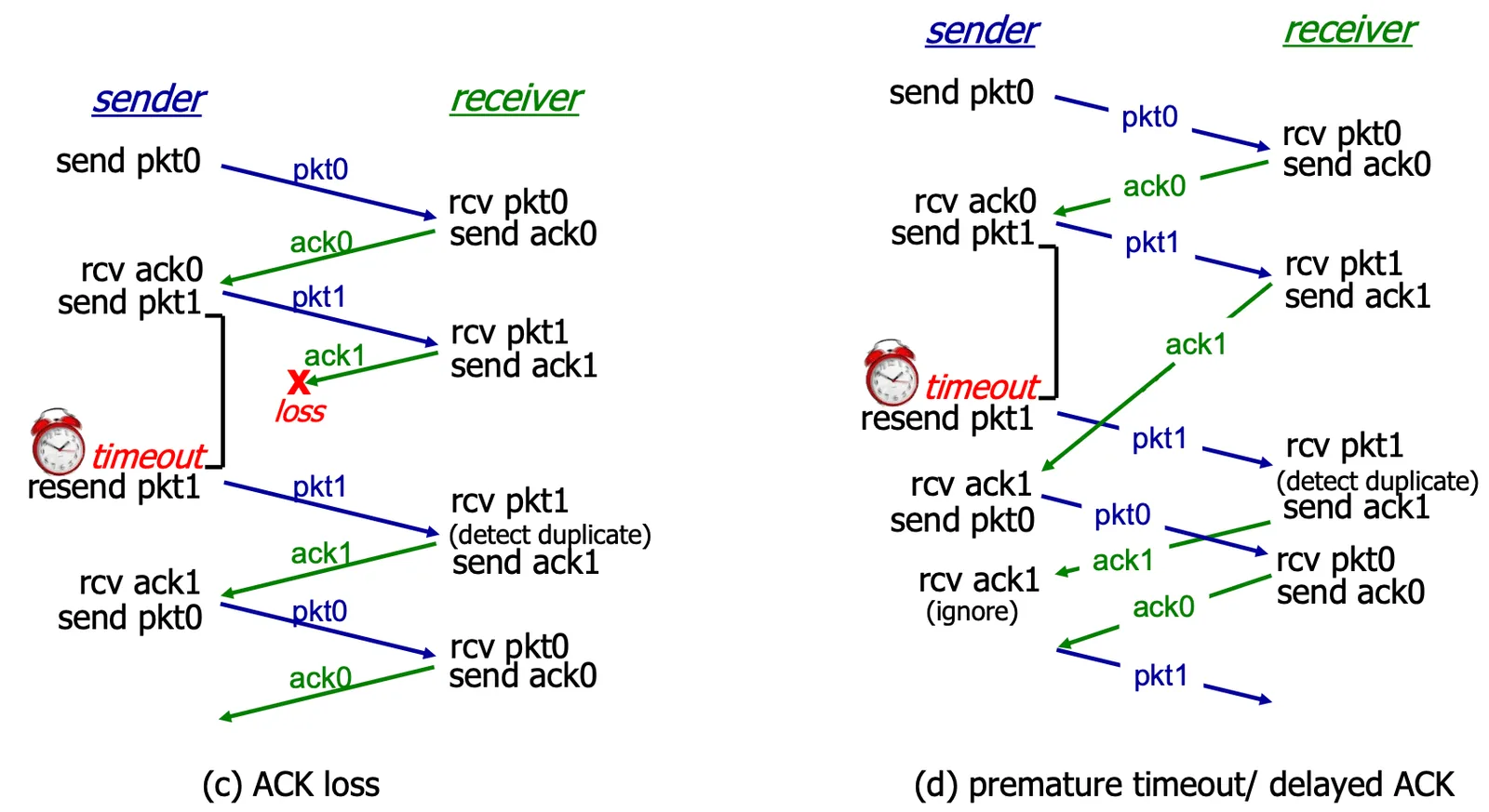
Action of rdt 3.0 2
- Case (a): No loss
- Case (b):
pktloss- 根據 FSM,
timeout後才會 resend pkt
- 根據 FSM,
- Case (c):
ACKloss- 根據 FSM,
timeout後才會 resend pkt - detect 到 duplicate 情況,就只發送
ACK不發送 data
- 根據 FSM,
- Case (d): premature
timeout- 若
timeout太短,但其實ACK有正常發送 - 在 FSM 中會被直接 ignore (Wait for
ACK1 state 的 loop)
- 若
Performance of rdt 3.0#
- 我們用 來衡量 (utilization, fraction of time sender busy sending)
- rdt 3.0 的大部分時間都在 busy waiting 因此 非常低。
Pipeline#
- 允許一次多個 sequence number 的同時傳送
- 需要更多 sequence number
- 需要更多 buffer space
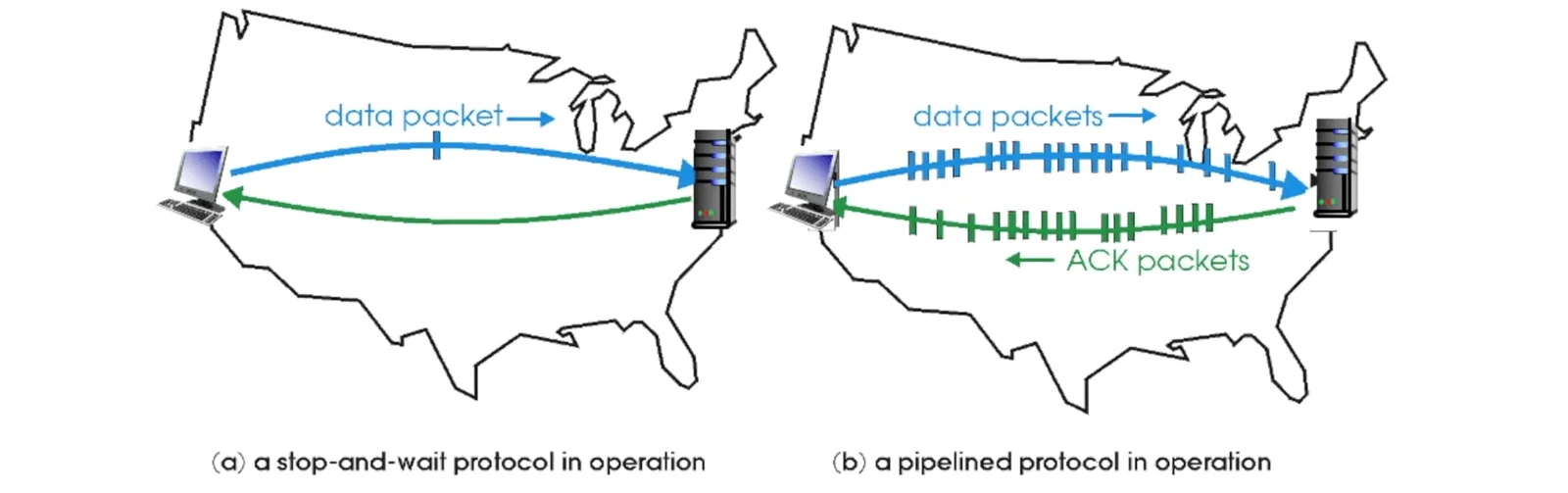
Pipeline 1
Go-Back-N sender/receiver (GBN)#
Sender
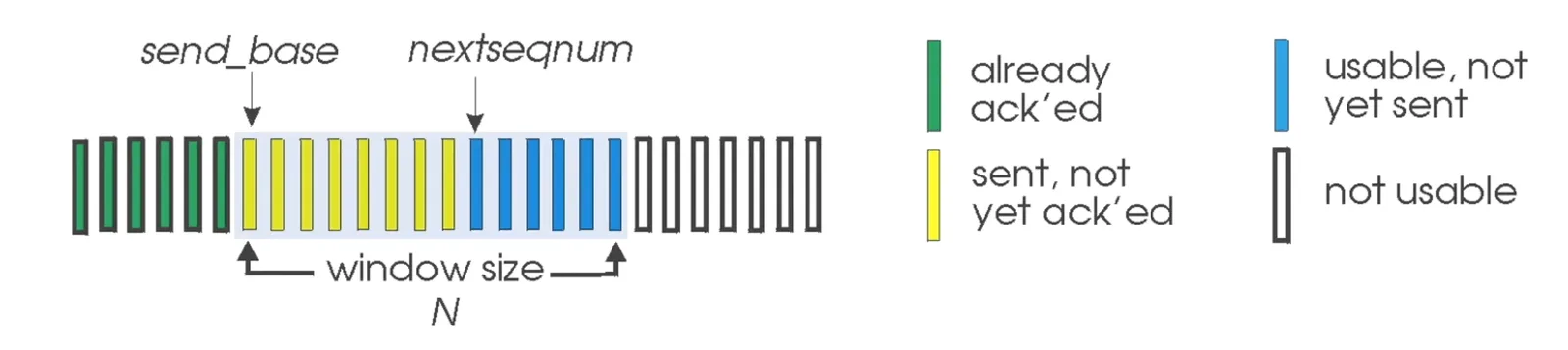
Go-Back-N sender/receiver 1
上圖是一整串 pkt
- 名詞
- 綠:已經被
ACK - 黃:送出但尚未
ACK - 藍:尚未送出但可以送出了
- 白:無法送出(可能是為確認 or 超過 限制)
send_base:目前尚未ACK最老pktwindow_size:可以一次送出的最大數量nextseqnum:尚未送出的最老pkt
- 綠:已經被
- Cumulative
ACK:ACK(n)- 運送成功就會讓
sned_base = n+1 - 不成功則看誰不成功,將
ACK調整至fail - 1,重新送fail起始到window_size大小
[!Note]
ACK(7)代表 7 號以前的所有pkt都已ACK - 運送成功就會讓
- Timer 會設定在
send_base上timeoutsender 會從 send_base 直到最後的未確認封包都重 送(window_size大小),最壞情況就是重新送 個
[!Note] 假設 sender 一直收到
ACK(7)即便 8, 9, 10 是好的,他也會重新運送整個window_size裡的pkt - FSM of Sender
Go-Back-N sender/receiver 2
Receiver
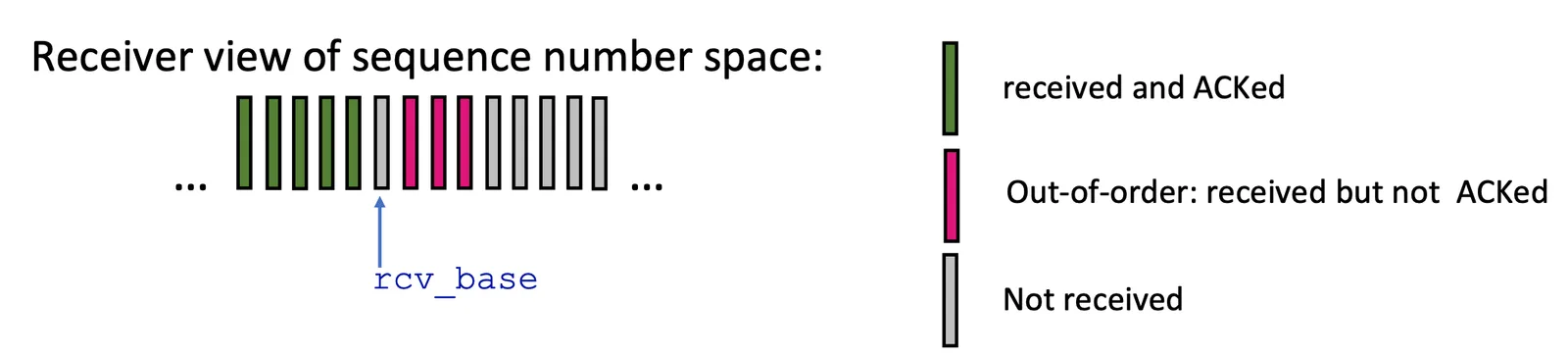
Go-Back-N sender/receiver 3
- 需要紀錄
recv_base,也就是下一個要收到的 in-orderpkt - 必須接收 in-order
pkt,若遇到不是in-order就 discard,不停發送ACK(recv_base - 1)
Selective Repeat (SR)#
Receiver 會 individually ACK
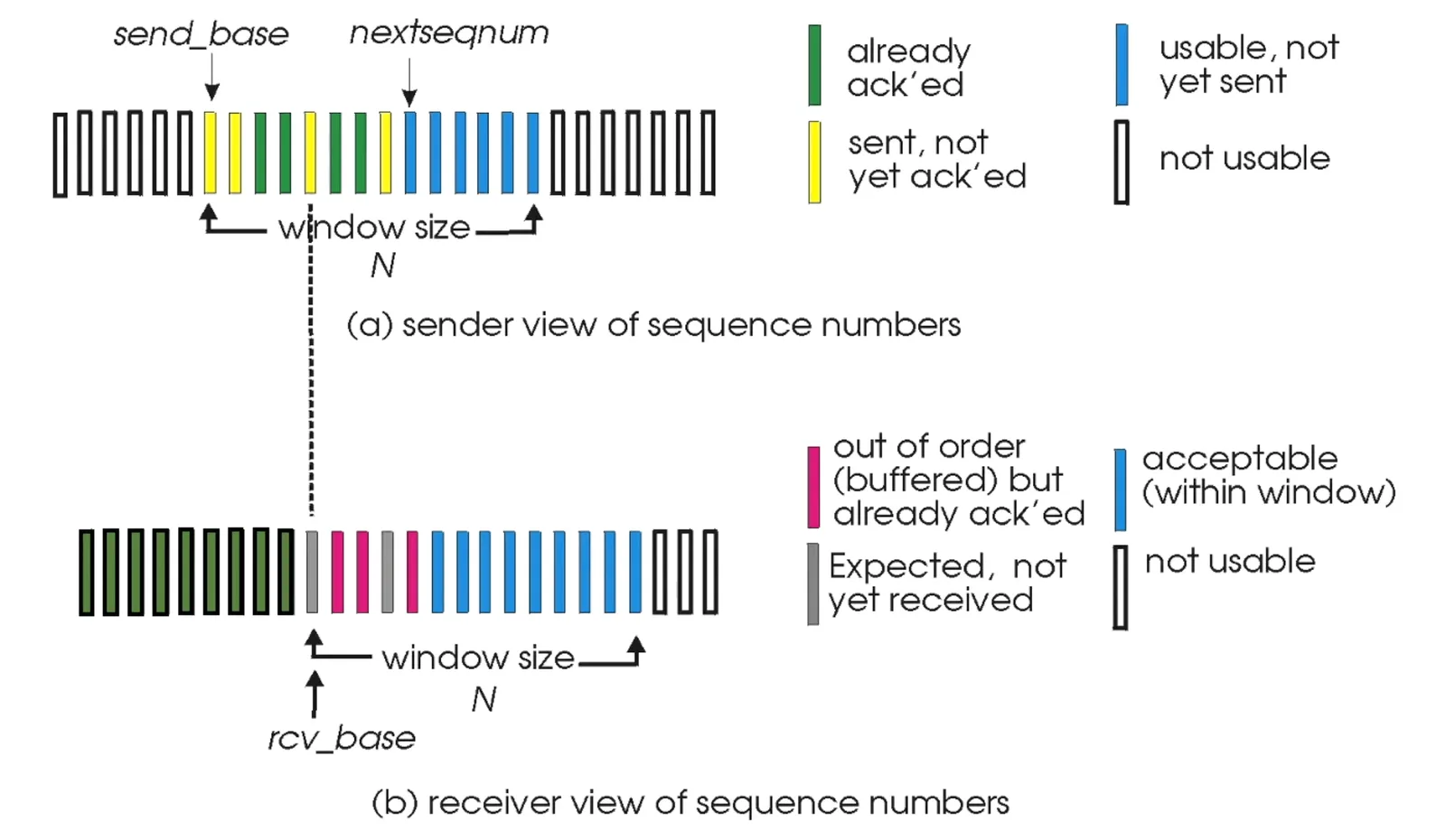
Selective Repeat 1
- 雙方都有
window buffer機制,為了要讓最後往上傳的pktin-order - 每個
pkt都要有 timer
Sender
- 只要
pkt seq #在 window 裡面就直接 send timeout(n):pkt seq n的 timeout 就把它重新發送- ACK(n) \in [\text{send_base}, \text{send_base} + N]:
- 標記
n個為 receive - 把
send_base挪到最小的unACK pkt
- 標記
Receiver
pkt\in [\text{recv_base},\ \text{recv_base} + N -1]:- send
ACK(n) - out-of-order:要 buffer 起來
- in-order:deliver 給上層
- 把
recv_base挪到
- send
pkt n\in [\text{recv_base} - N,\ \text{recv_base} - 1]- send
ACK(n)
- send
- otherwise:ignore
TCP (Connection-oriented transport)#
- point-to-point (sender to receiver)
- reliable in-order byte stream
- 沒有
message boundary所有 sender send 的 data 都是連續的,所以會混再一起送
- 沒有
- pipelined
- TCP congestion, flow control 可以改
window_size
- TCP congestion, flow control 可以改
- full duplex
- 雙向傳輸,sender receiver 不一定只能收獲只能送
- 每個
pkt有自己的MSS: maximum segment size
- connection-oriented
- 為了達到這件事需要做三次 handshake
- flow control
TCP segment structure#
TCP seq ##
- 每個 bytes 都當成
seq # - 記錄每個 segment 開始的 bytes
- 使用 cumulative
ACK:雙方下一個想收收的的下一個seq #- 若遇到 out-of-order 每個 TCP 不一定做什麼
- sender/receiver view
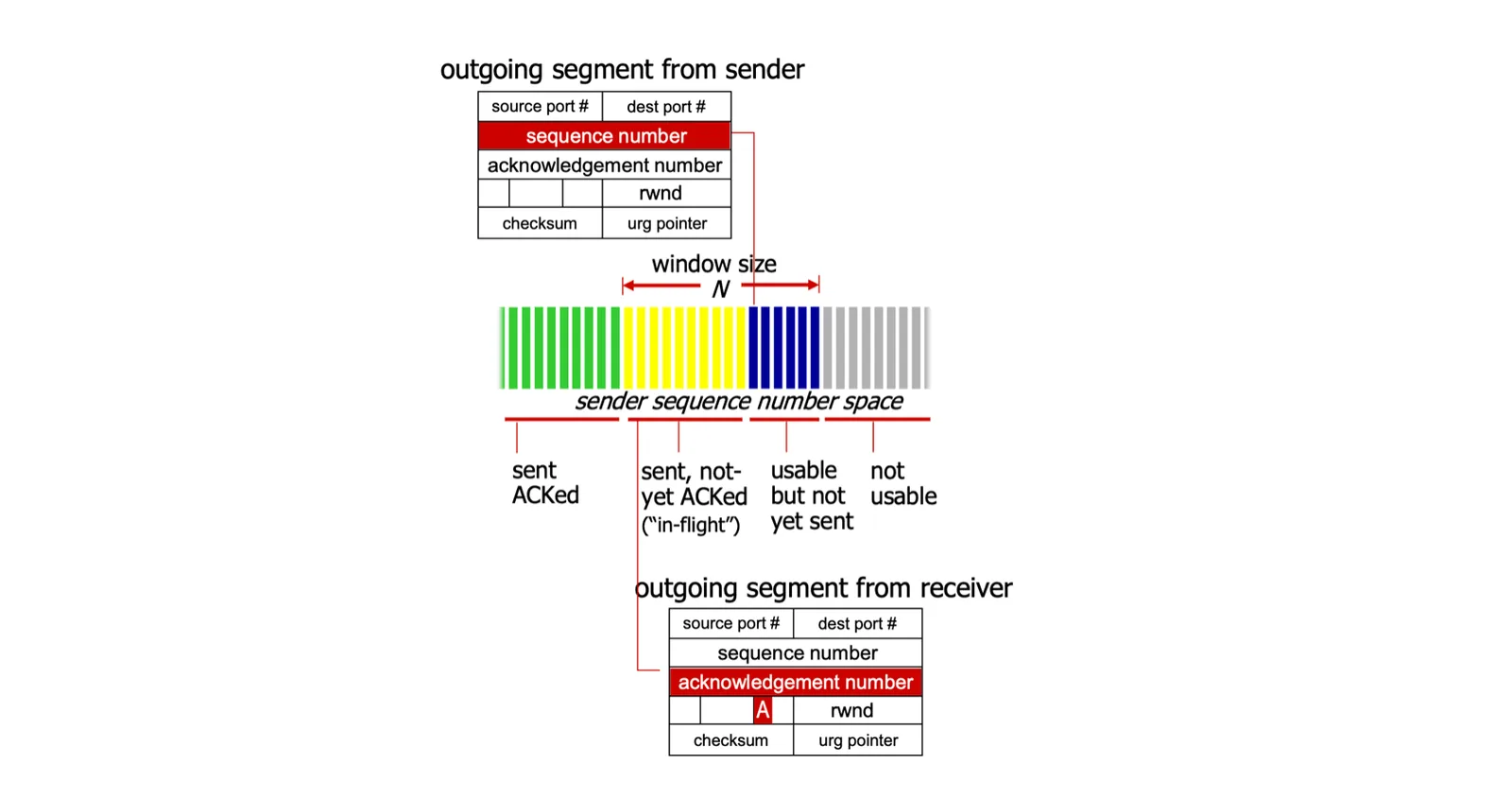
TCP seq # 1
Timer#
- :premature timeout
- :太慢會導致 segment loss 風險大
- 通常用
SampleRTT是送出去到 回來接收到ACK- 忽略重新傳送
- 通常會用 average(加權平均):exponential weighted moving average (EWMA)
- 通常為最佳
-
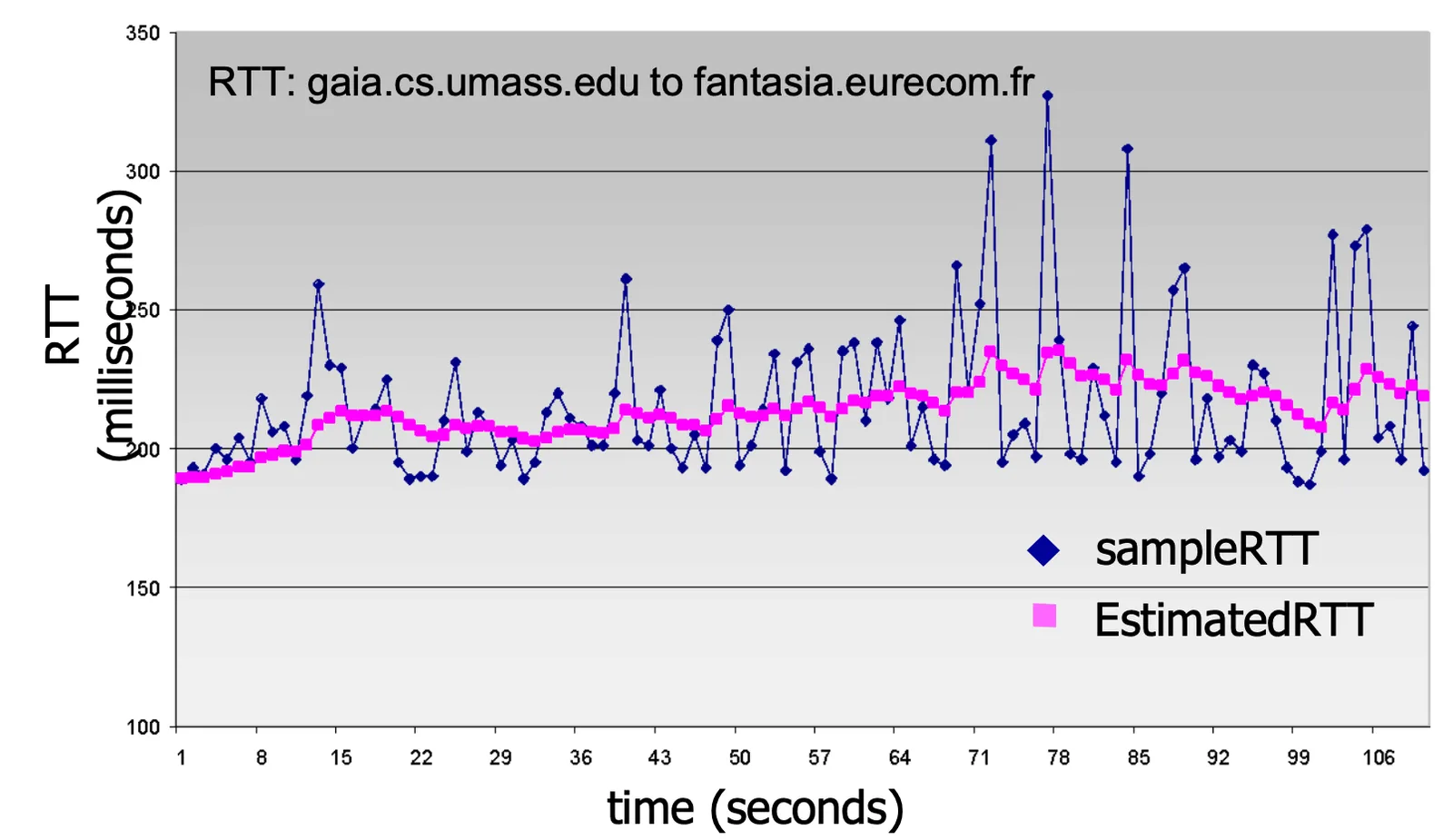
Timer
- 但我們無法直接使用 當作 timeout 不然會一直 premature
- 要加上一個 safety margin 通常會跟 variation 有關(實際值, 預測值)
- 通常最佳
Reliable data transfer#
- 在 unreliable 的 IP service 上建立 rdt 服務
- pipeline segment + cumulative ACK + single timer
- 若需要 retransmission 會使用 duplicate ACK
Sender event#
- 把從上層解包的資料標上
seq # - Start timer 為
- timeout
- 只把最老重新的送出
- recv ACK
- 更新
window - 有尚未被 ack 的
pkt要重新 set timer
- 更新
ACK generation#
| Receiver event | TCP receiver action |
|---|---|
receiver 接收到 in-order segment,所有 seq # 正確,已被 ACK | delay 回覆 ACK,最多等 500ms,看看下個 segment 是不是來了 |
receiver 接收到 in-order segment,所有 seq # 正確,但有一個 pending ACK | immediately 回覆 ACK,可以一次解決兩個 |
receiver 接收到 out-of-order segment,有 seq # 缺失 | immediately 回覆 duplicate ACK,表示需要接收缺失的資料 |
| receiver 接收到用來補 out-of-order gap 的。 segment | immediately 回覆 ACK,表示需要接收缺失的資料,但必須是 lower end 的 gap 才會進行動作。 |
fast retransmit#
timeout通常會長一點,要設計彌補機制- 用 duplicate ACK 來得知要趕快 retransmit
- 發現出現 triple duplicate ACK,必定有前位 segment 沒收到,要重新發送
fast retransmit
TCP Flow Control#
- TCP 要把自己出裡過的 segment deliver 到 app. layer
- 寫進 TCP socket buffer 然後 app layer 去讀
- 寫入 buffer 速度過快會產生資料丟失,要根據剩餘 avalible space 來決定 control
- 有一個
rwnd參數,就是剩下的 free,不設定RcvBuffer的話 default 是 4096
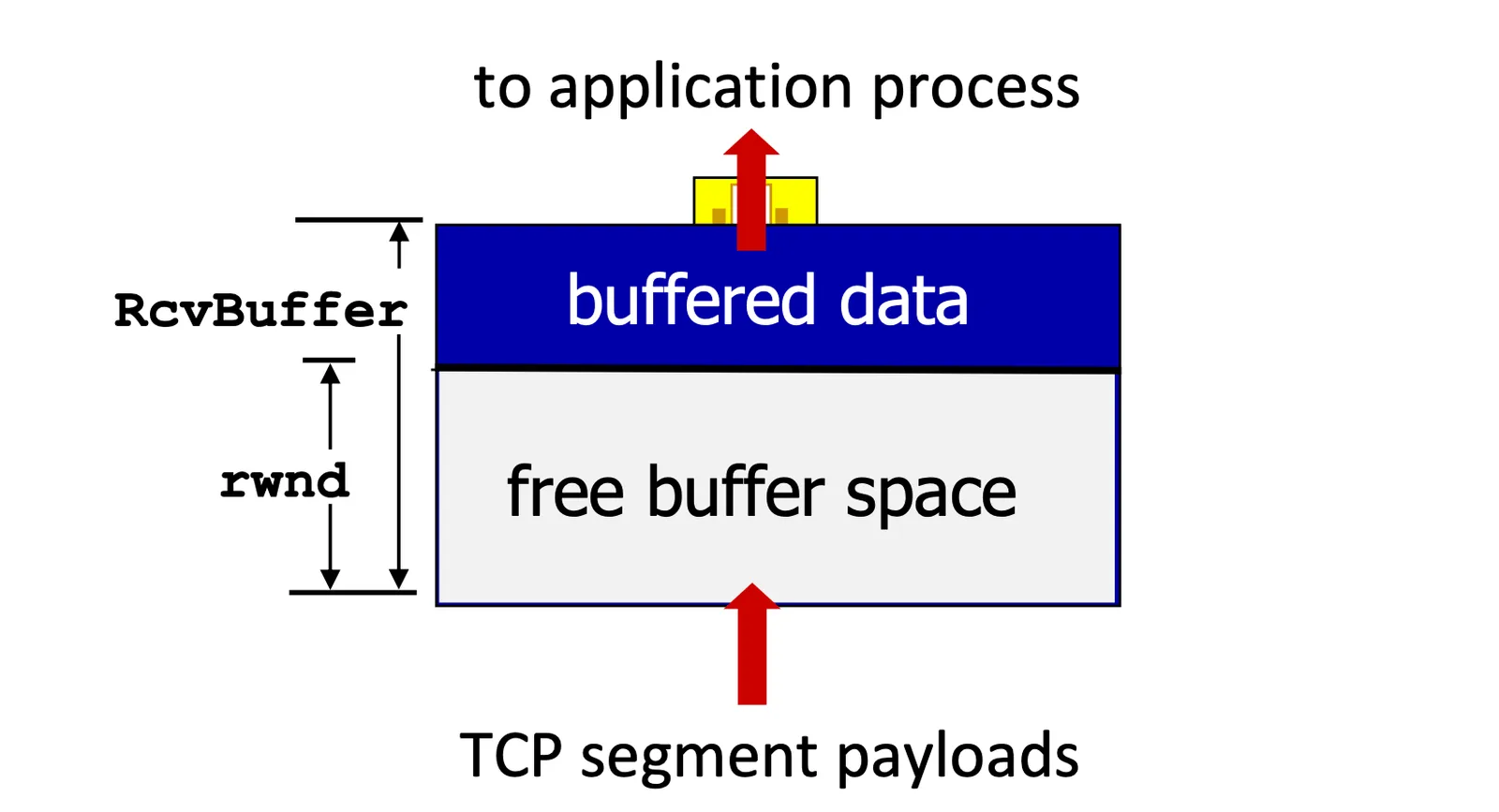
TCP Flow Control
TCP connection managment#
- “handshake” 要讓兩邊的 data sync 一下
- initial,
rwnd, 是否 accept,seq #
- initial,
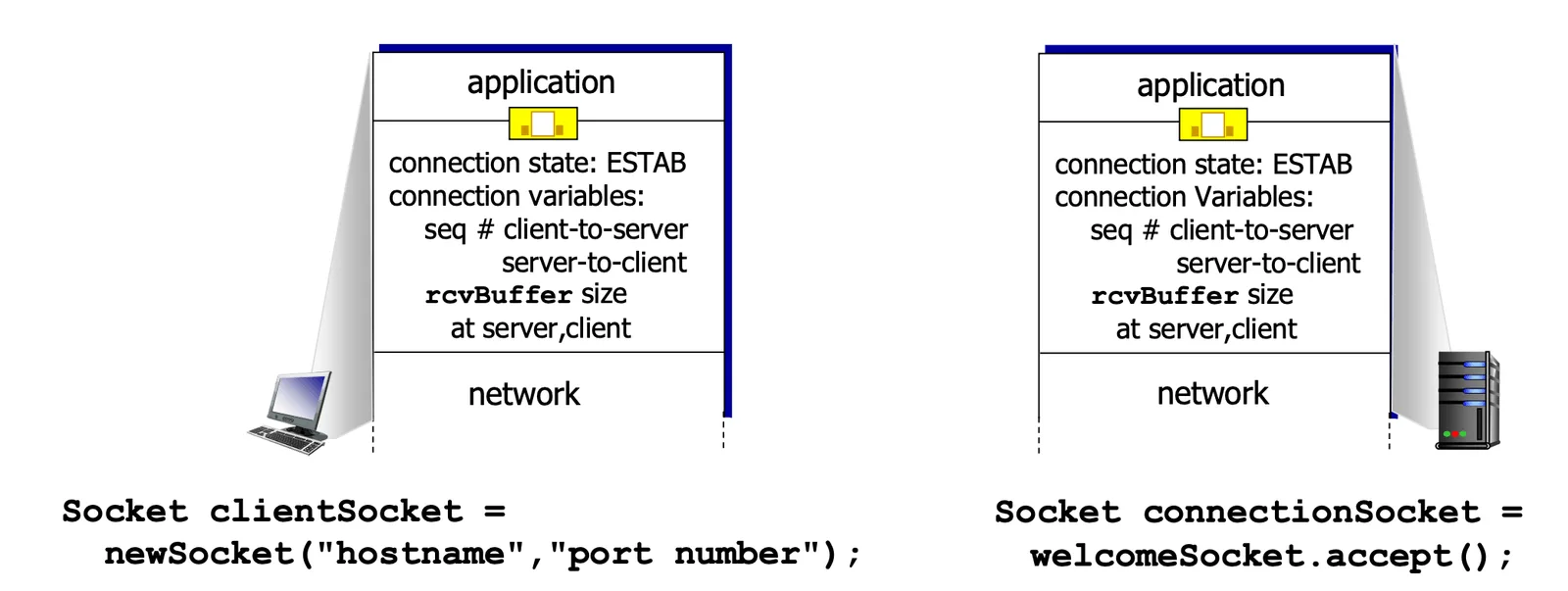
TCP connection managment
3-way handshake#
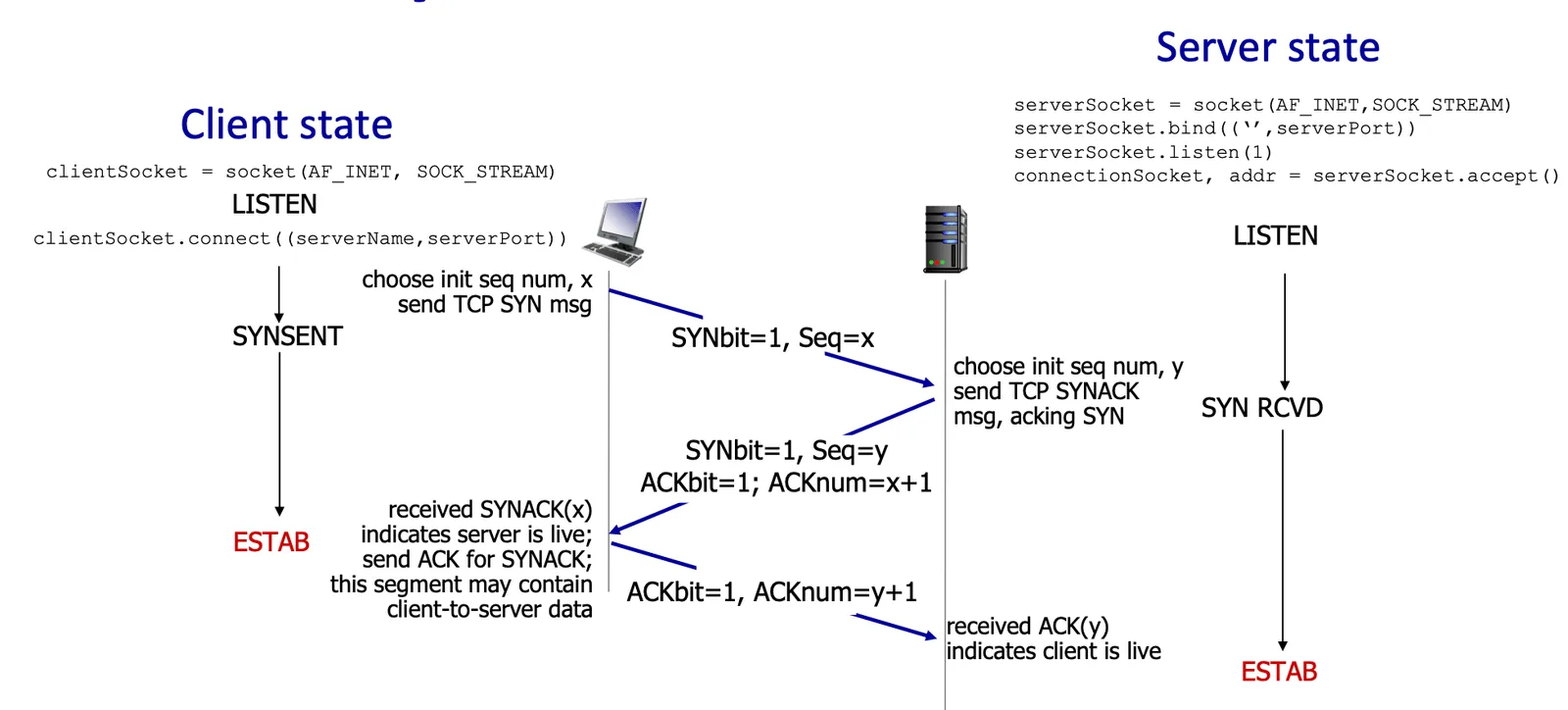
3-way handshake 2
- 可以避免 server 認為你的 request 是一個新 request
- SYN server to client
- SYN client to server
- ACK server to client
- 要 close connection
- FIN fin bit 設定成 1(兩端都要)
- ACK
Congestion Control#
- Congestion:一次送太多,卡住了,是再講 network 本身內部發生的問題(router)
- lost
pkt(buffer overflow in router) - long delay (queueing in router buffers)
- lost
Cost of Congestion#
Senario 1#
- :原始資料
- :throughput
- :output link capacity
- 一個 router, infinite buffer
- no-retransmission
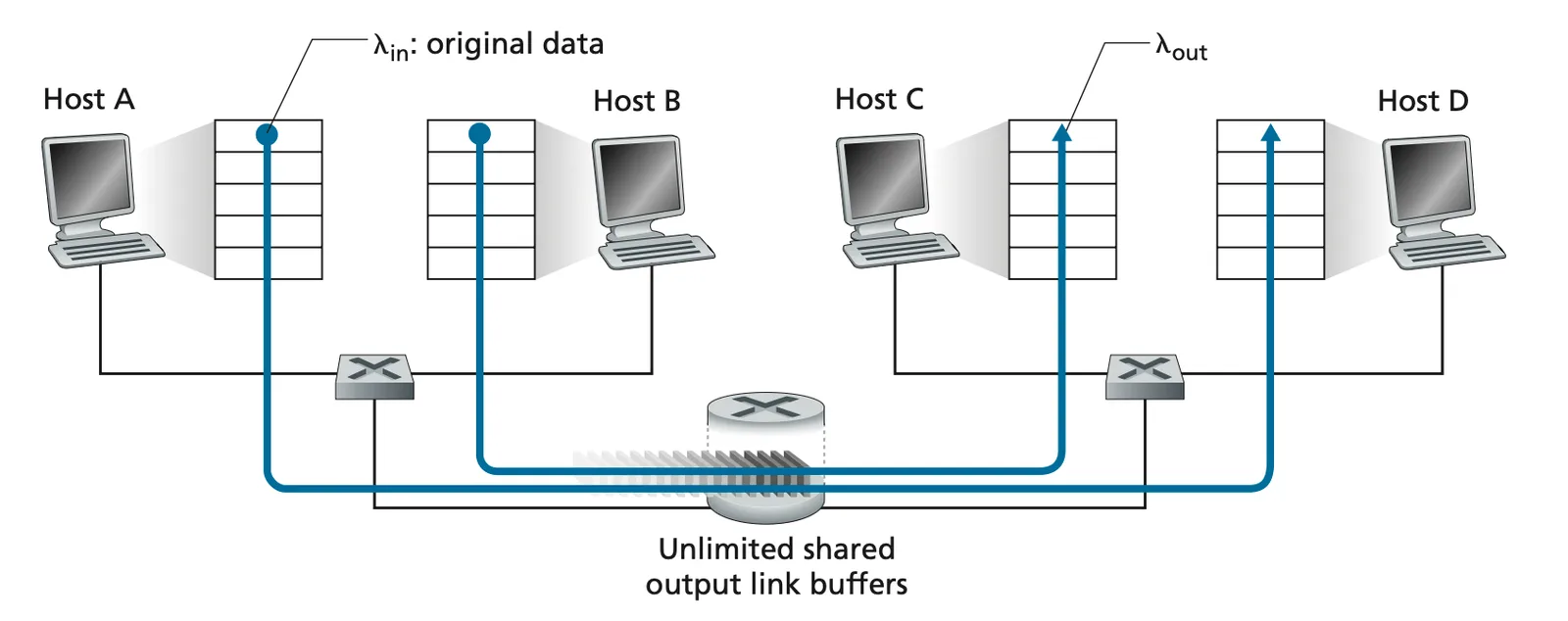
Senario 1 1
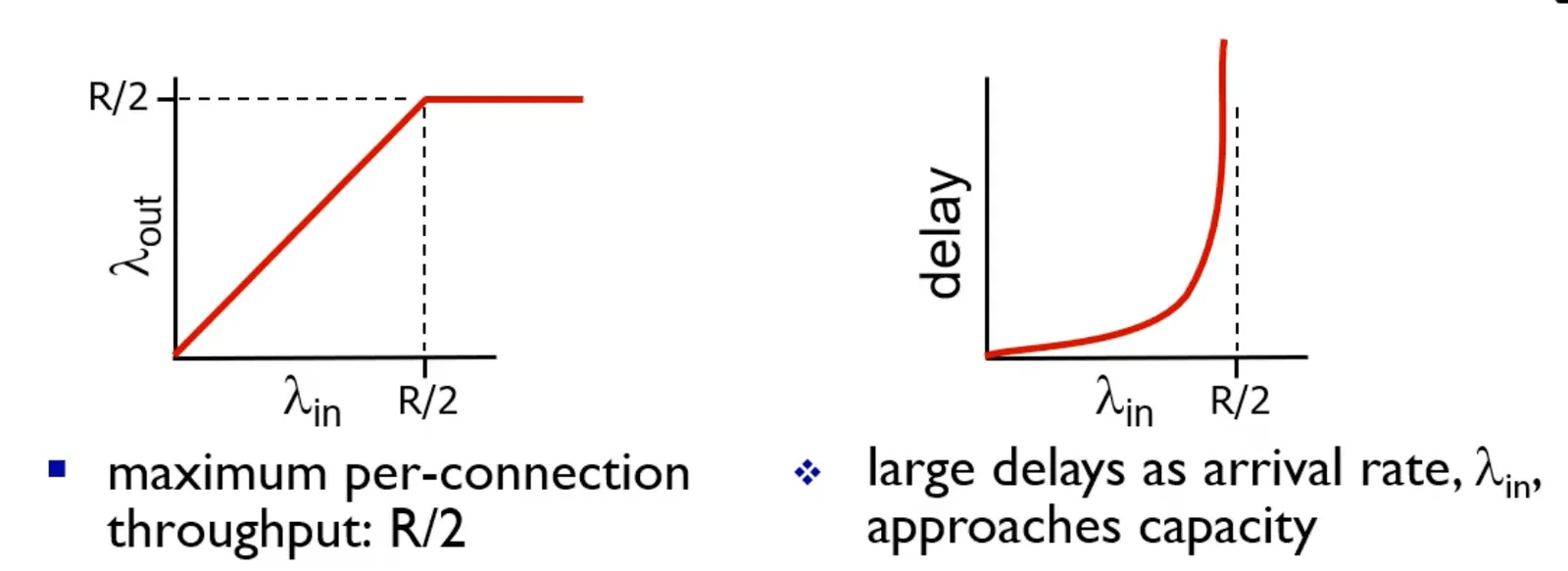
Senario 1 2
- , 成正比,但當 時,就停下來了。
- 會暴增
- 越多人在等,queue 越長,越有 delay (exponential 增加)
Senario 2#
- :原始資料
- :原始資料加上 retransmit
- :throughput
- :output link capacity
- 一個 router, finite buffer
- 假設 sender 有 perfect knowledge,知道啥時 overflow 就不送
- 假設 sender 知道 pkt loss.
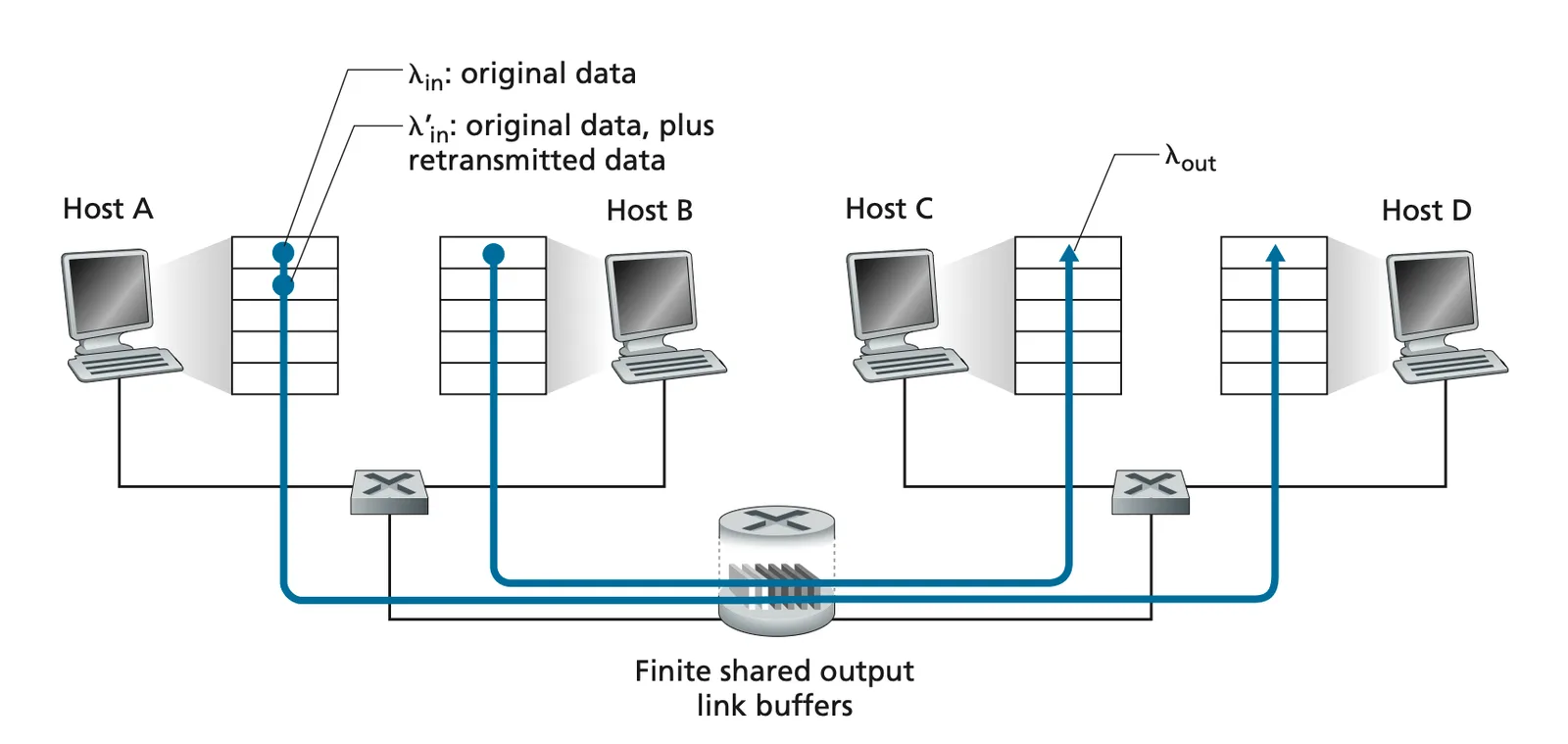
Senario 2 1
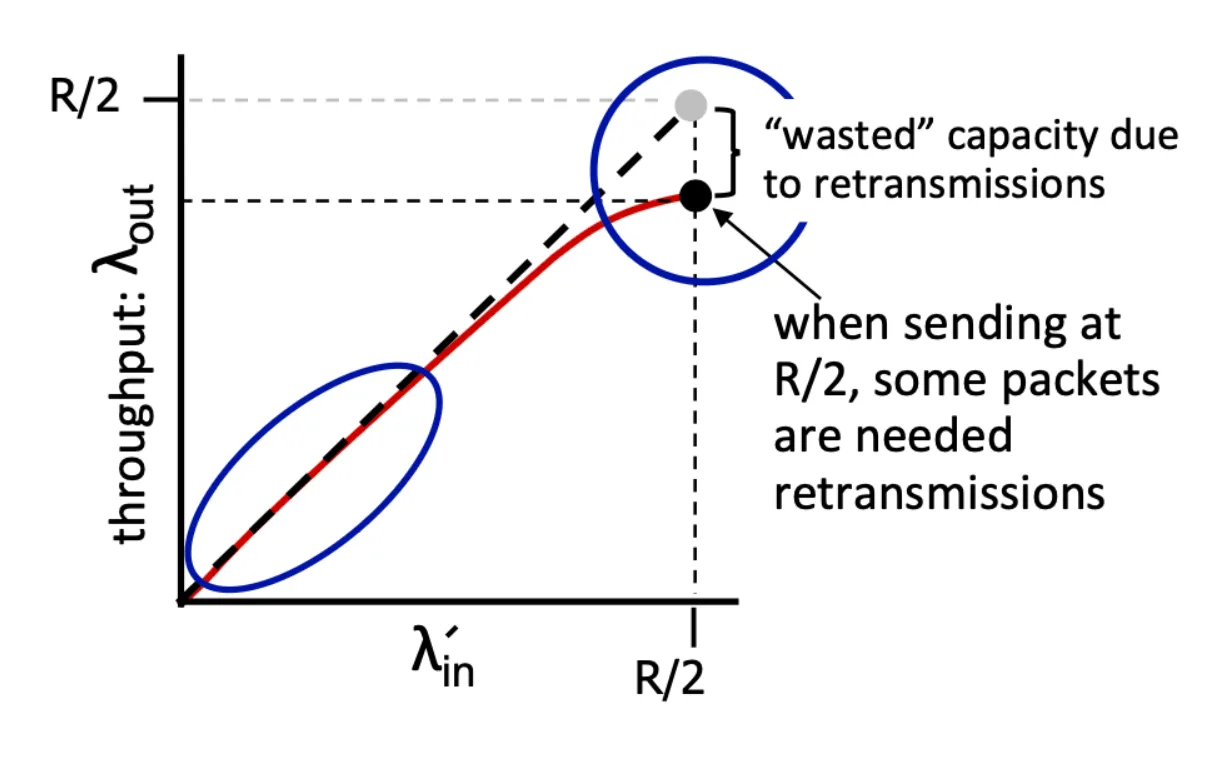
Senario 2 2
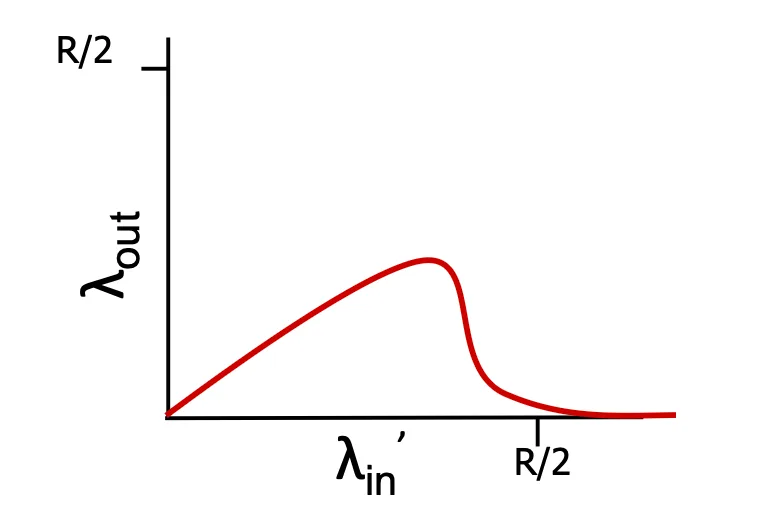
- 傳送 的資料但裡面有一些是重複無效資料,因此 達不到
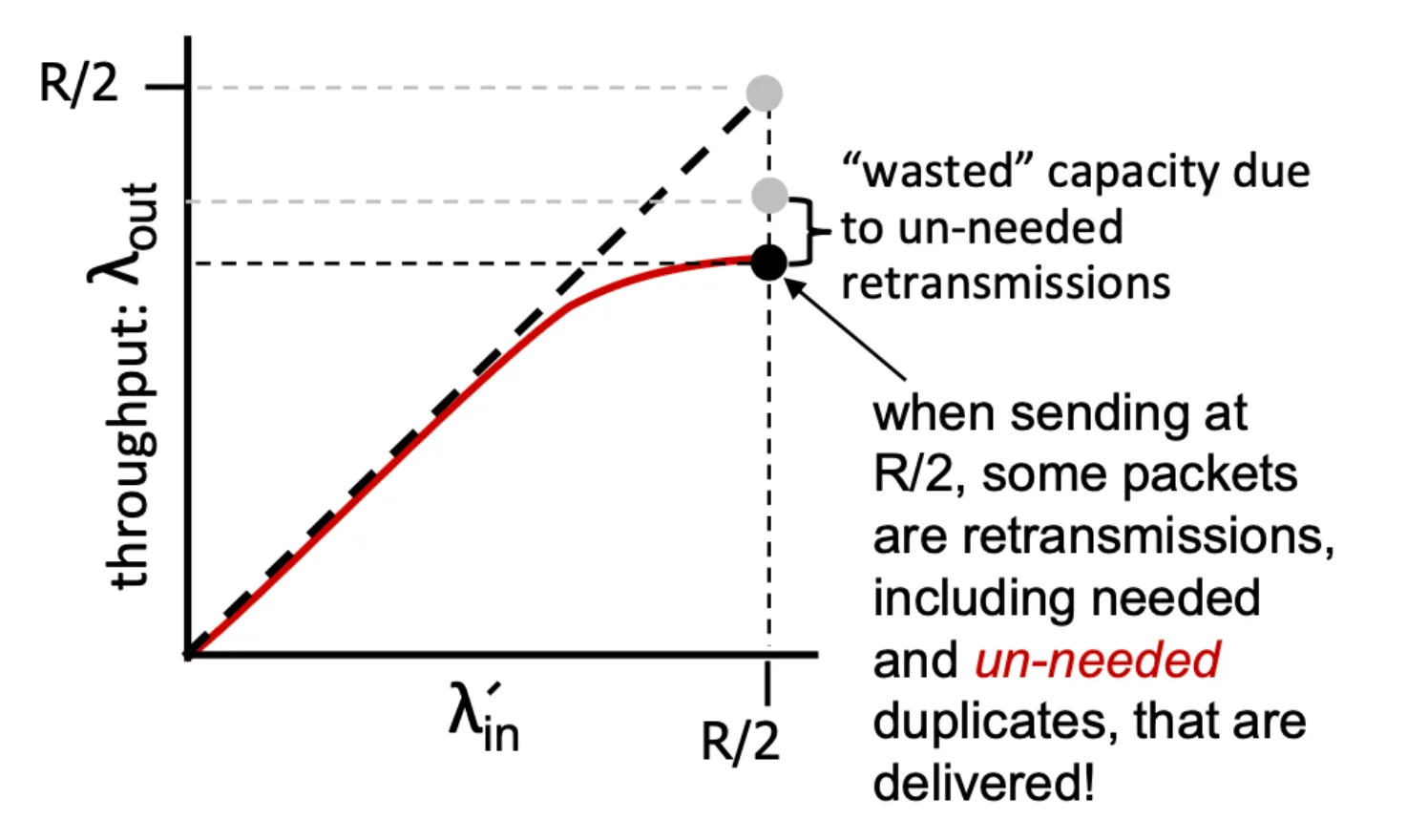
Senario 2 3
- 重傳會不停收到一樣的資訊,會導致無效資料又增加
- goodput 代表真正有效的 throghput.
Senario 3#
- :原始資料
- :原始資料加上 retransmit
- :throughput
- :output link capacity
- 四者互為對方的 sender/receiver
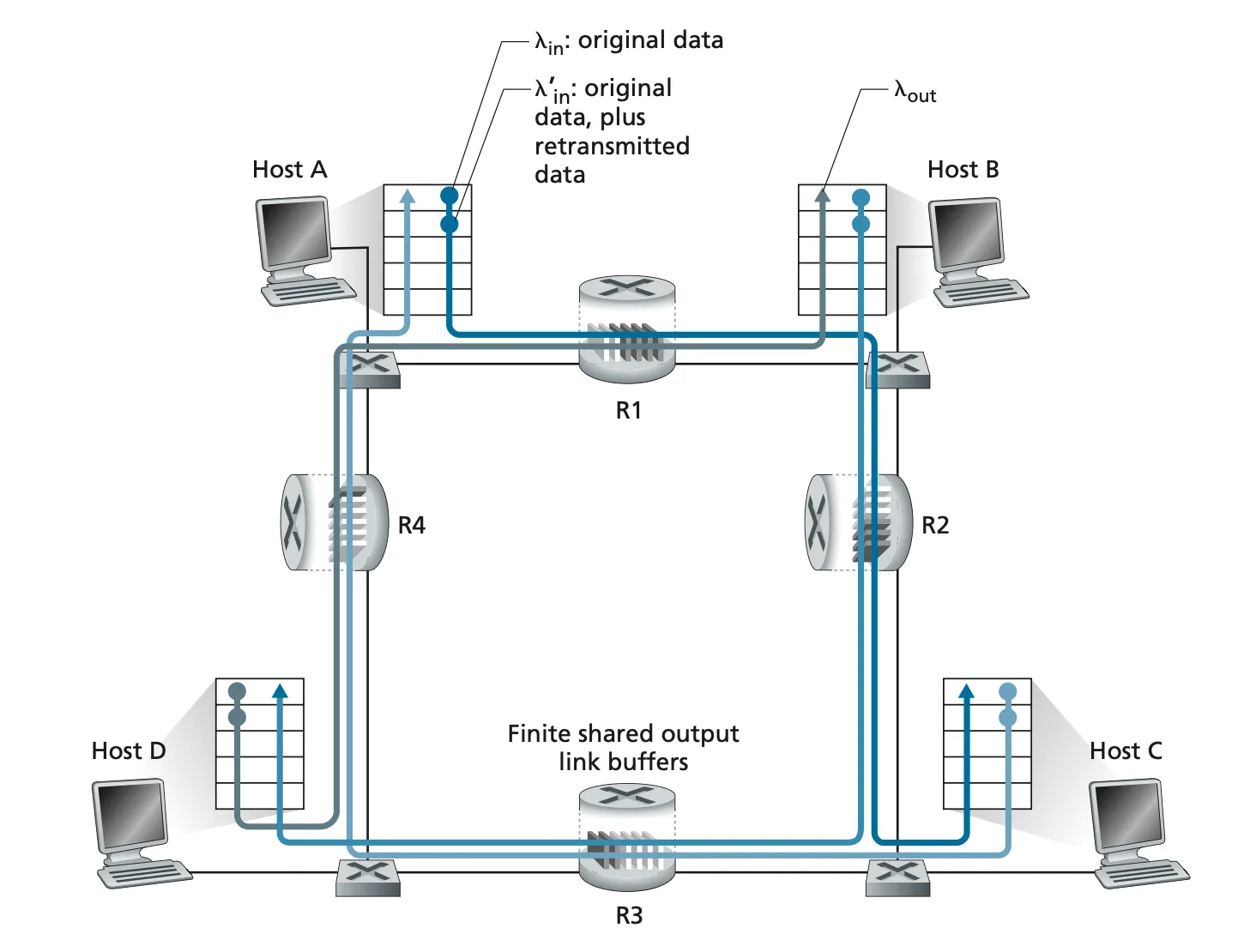
Senario 3 1
Senario 3 2
- 兩條共用 router 的人,若在這個情況下,一方的速度受限於他走的第一個 router 而非無限大,但另一方無上限。在這個情況就可以發現,所有 connection 都會佔據大優勢在第一個 router 但在第二個 router 會完全卡死(搶輸),
- 下游 router queue 滿了,產生 downstream transmission
pktloss 導致上游無論有多快速的 transmission rate,upstream transmission 一樣是 0
Congestion Control type#
- End-end congestion control:
- TCP 使用的
- 無法直接從 router 得知是否產生 congestion
- 從
loss,delay來做 inference
- Networ-assisted congestion control
- Router 會有 direct feedback 告訴你是否產生 congestion
- TCP ENC, ATM, DECbit protocol
TCP Congestion Control#
AIMD (Additive Increase Multiplicative Decrease)#
- 是一個 distribute, asynchronous algorithm
- 增加 sending rate 直到出現
loss- 每輪次 最多增加 1 segment 的速度
- 出現
loss後減少 sending rate 一半- 砍一半
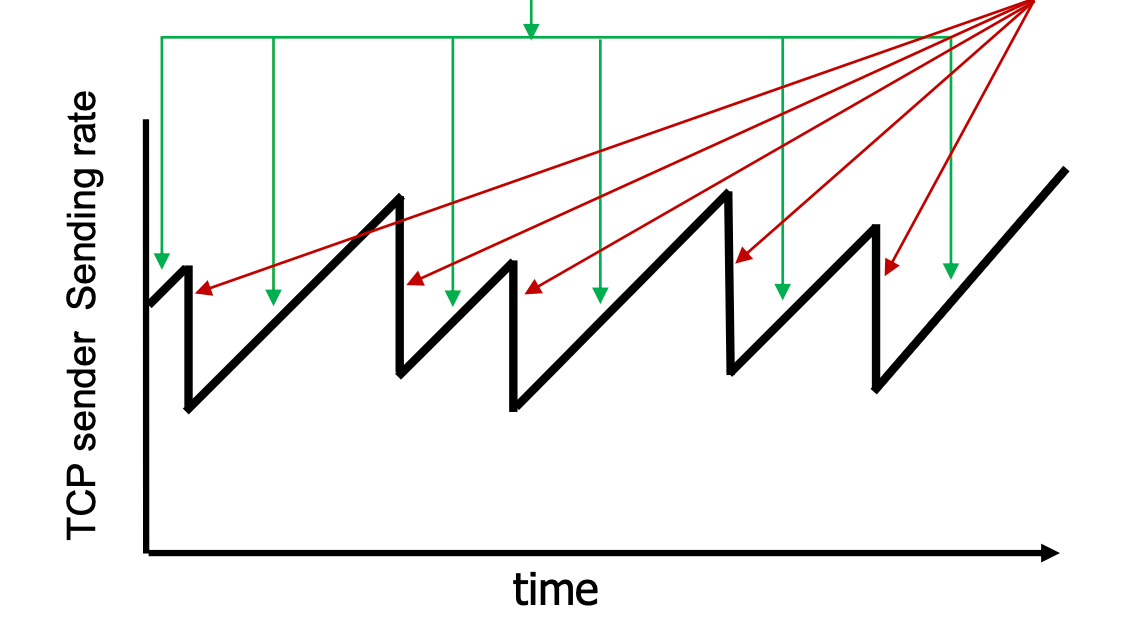
AIMD
Multiplicative decrease#
- TCP Reno:收到 triple duplicate ACK 表示有
loss發生,sending rate 砍一半 - TCP Tahoe:如果產生
time-out就把 MSS (Maximum Segment Size) 設定為 1
TCP congetion window#
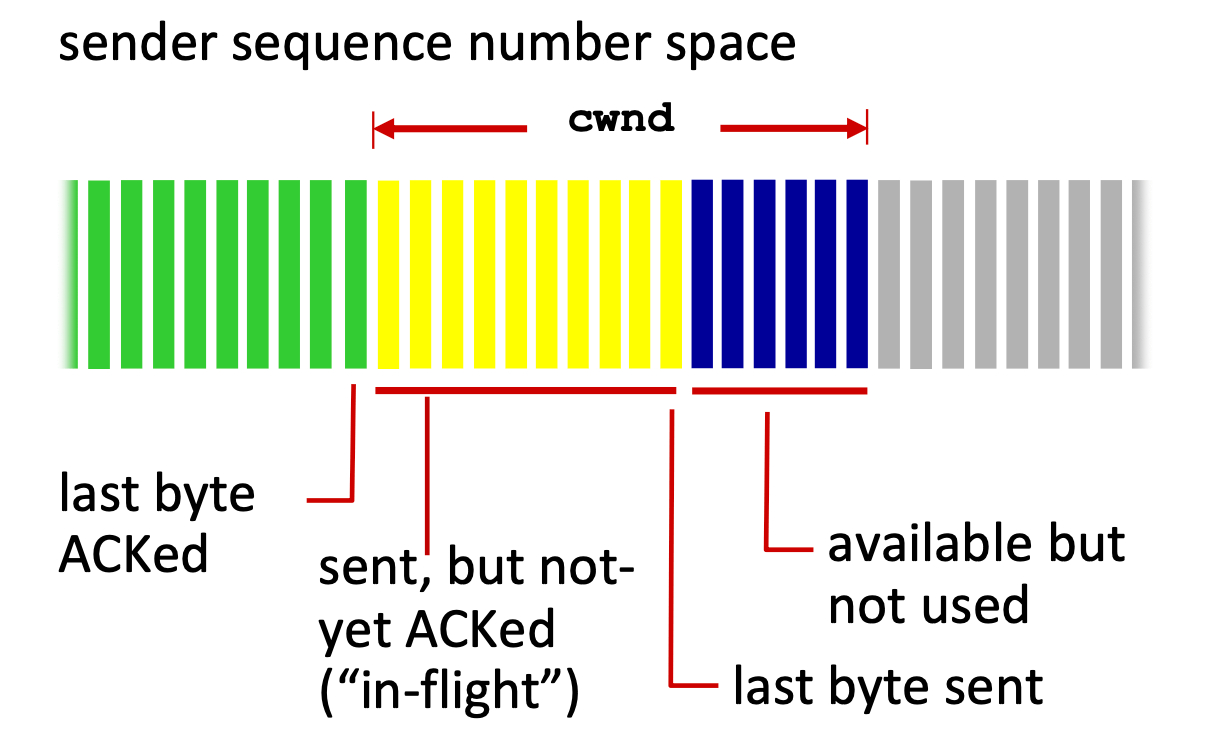
TCP congetion window
- 是一個動態調整的「同時在網路上未被 ACK 的資料量」(一次傳多少)
TCP slow start#
- 初始化
- 每輪次 double ,直到
loss發生
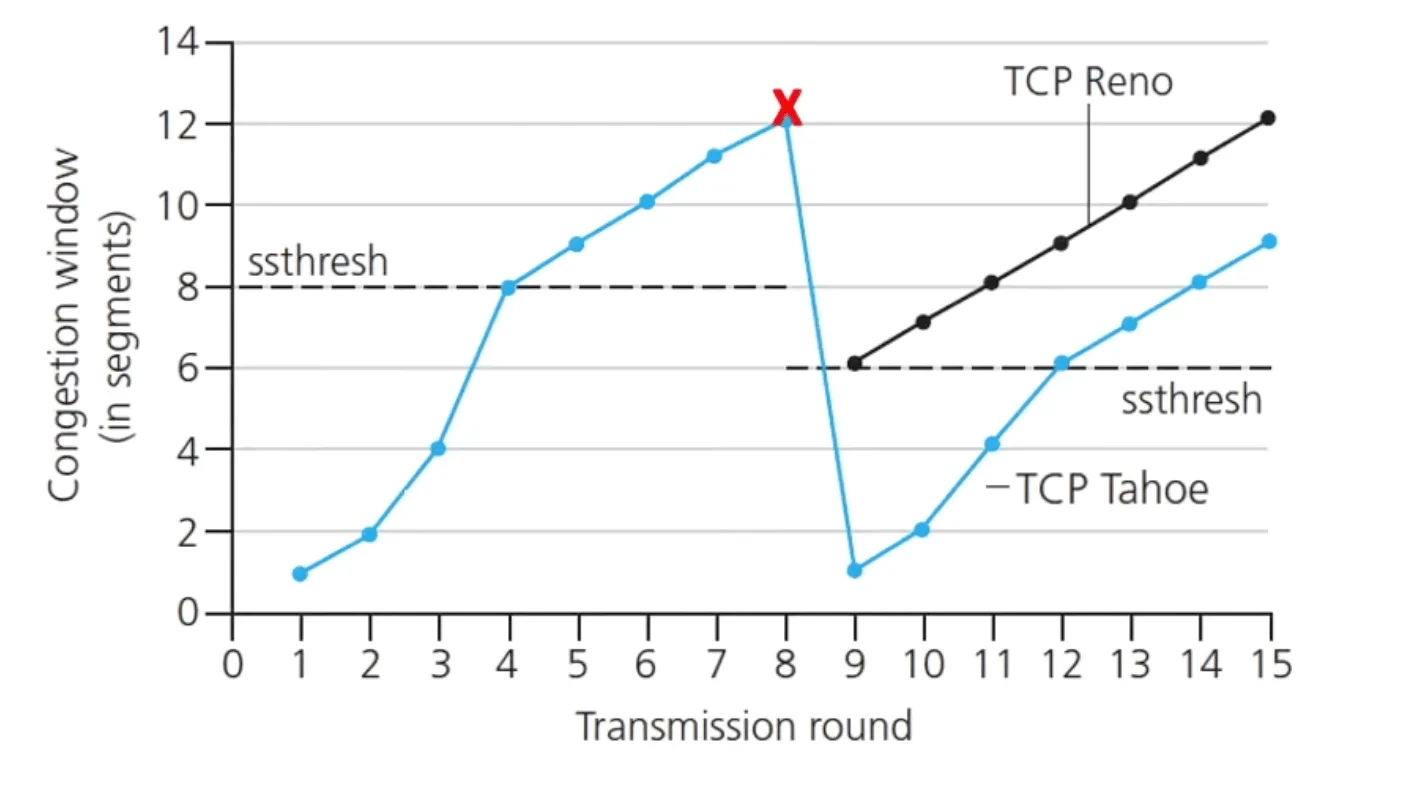
TCP slow start
- 用來記錄每次 exponential transition to linear 的點
- 在 以下用 exponential 增加
- 在 以下用 linear 增加
- 每次
lossevent 前更新
FSM of TCP congestion control#
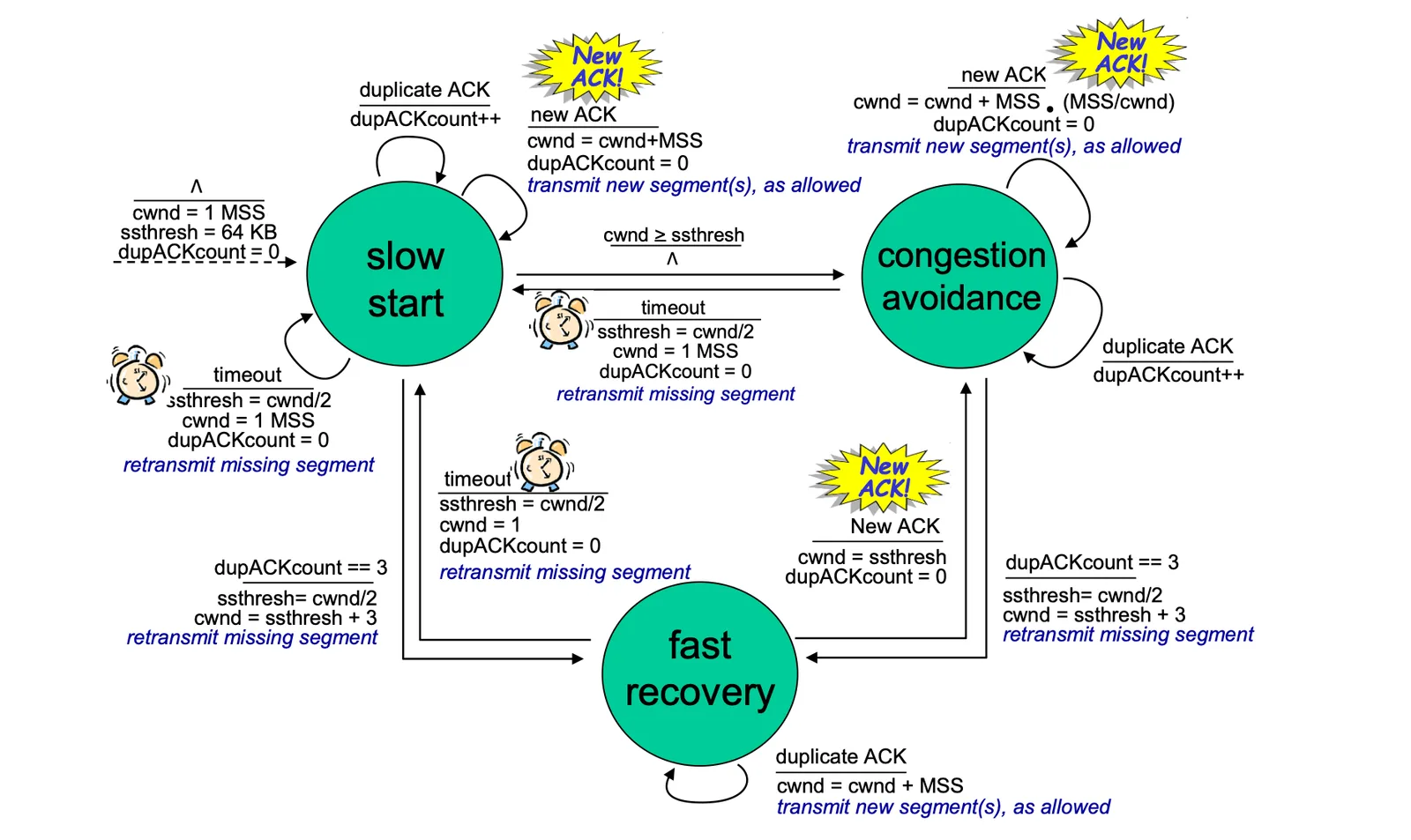
FSM of TCP congestion control
- 產生 dupACK 或是
timeout都有可能產生問題,但其實不一定,所以有以下方法
Explicit Congestion Notification (ECN)#
- 是一種 network-assisted 的 Congestion control
- Router 發現 congestion 會在 IP header (ToS 欄位) 放入
11原始為10 - Destination 收到這個 header 後會 sets ECE 為
1(在 Transport Layer)
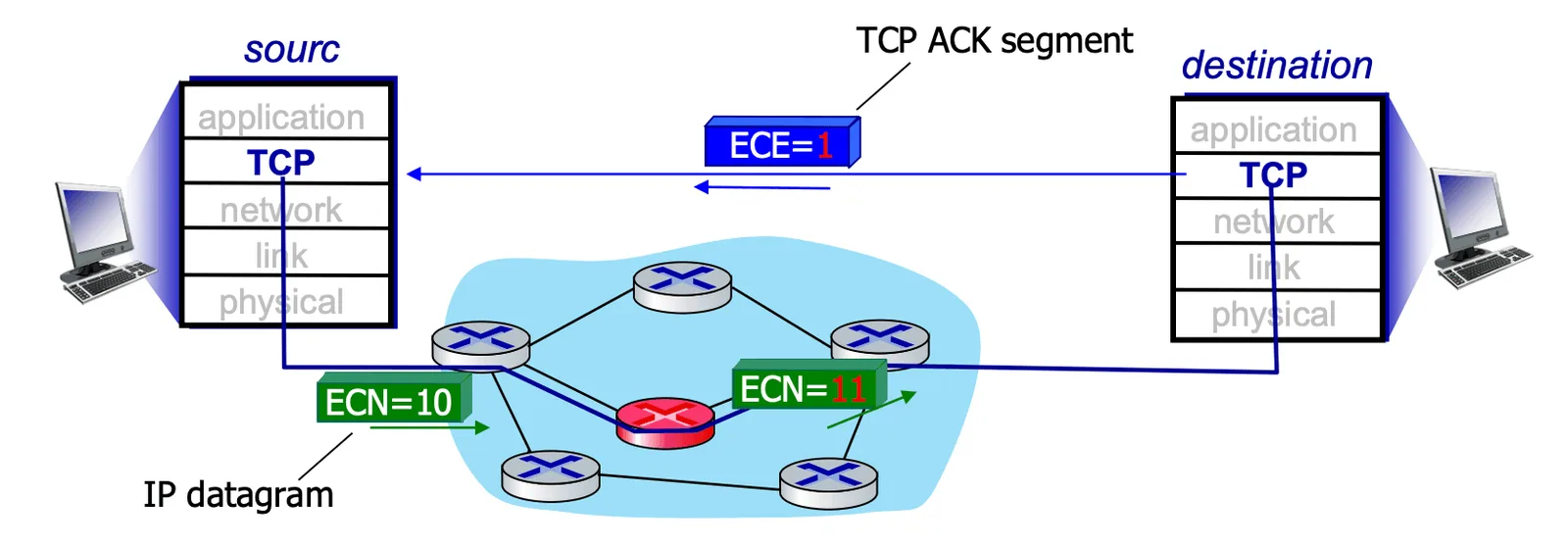
Explicit Congestion Notification
- 只有某些 TCP 才能做這件事
TCP Fairness#
- TCP 是完全分散式的系統,因此會根據各種情況去做 Congestion Control
- 因此我們要考慮每一台 edge 遵循 Congestion Control 是否會是公平的獲得
- 在宏觀的角度下來看,我們會維持在一個平均之上,但微觀來看會有不斷地調整,在 congestion avoidance state 之下,就會有這樣線性的情況
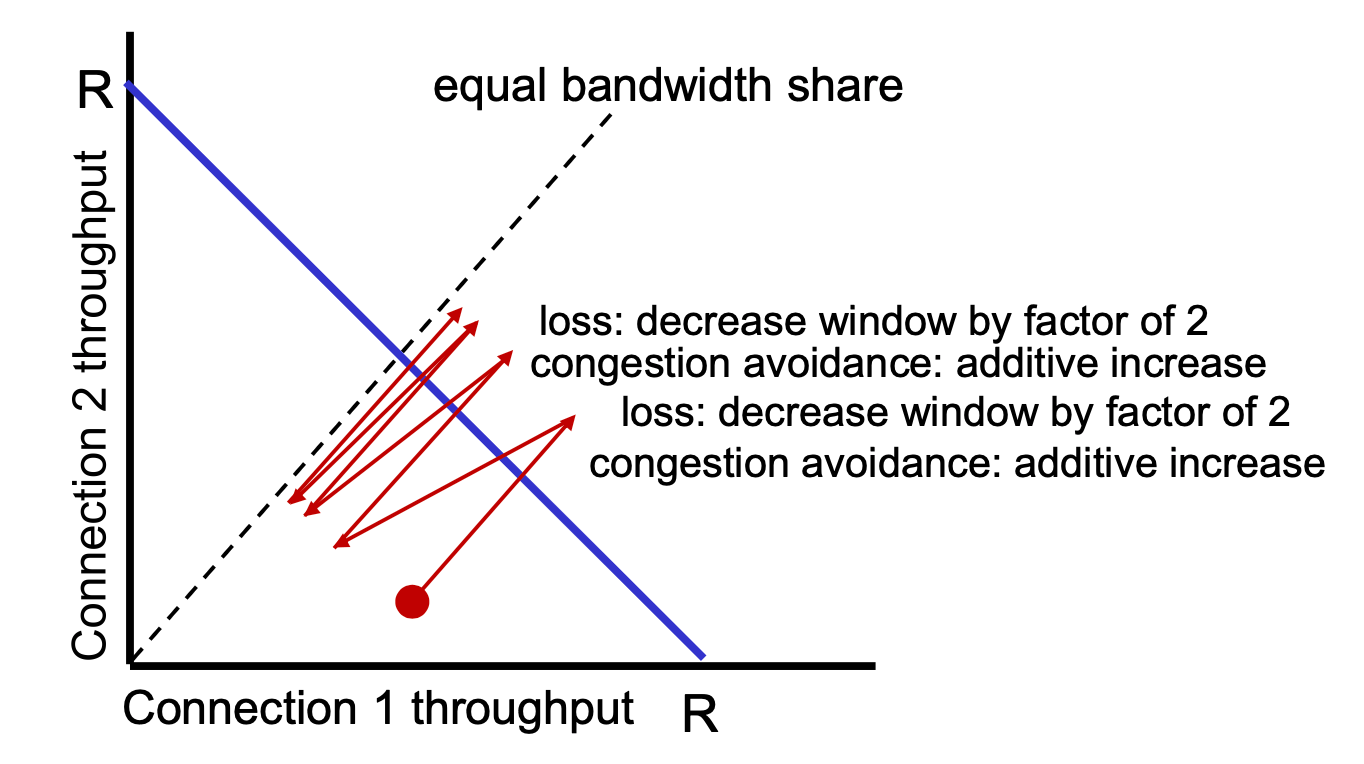
TCP Fairness
- 沒有 central 的中控,所以還是微觀下不穩定是無可畢免的
Back to the content
NTU Computer Networking
2025 Fall
← Back to the content