CPU Scheduling#
CPU 希望可以 maximize usage 或是 minimize time,需要做 Scheduling
Basic Concepts#
CPU-I/O Burst Cycle#
從 Process 角度來看,只做兩件事
- CPU Burst 進行運算
- I/O Burst 等待 I/O event
我們稱為 CPU-I/O Burst Cycle,而從 System 的角度來看,必須讓 CPU 在某個 I/O Burst 的時間去做別的事情
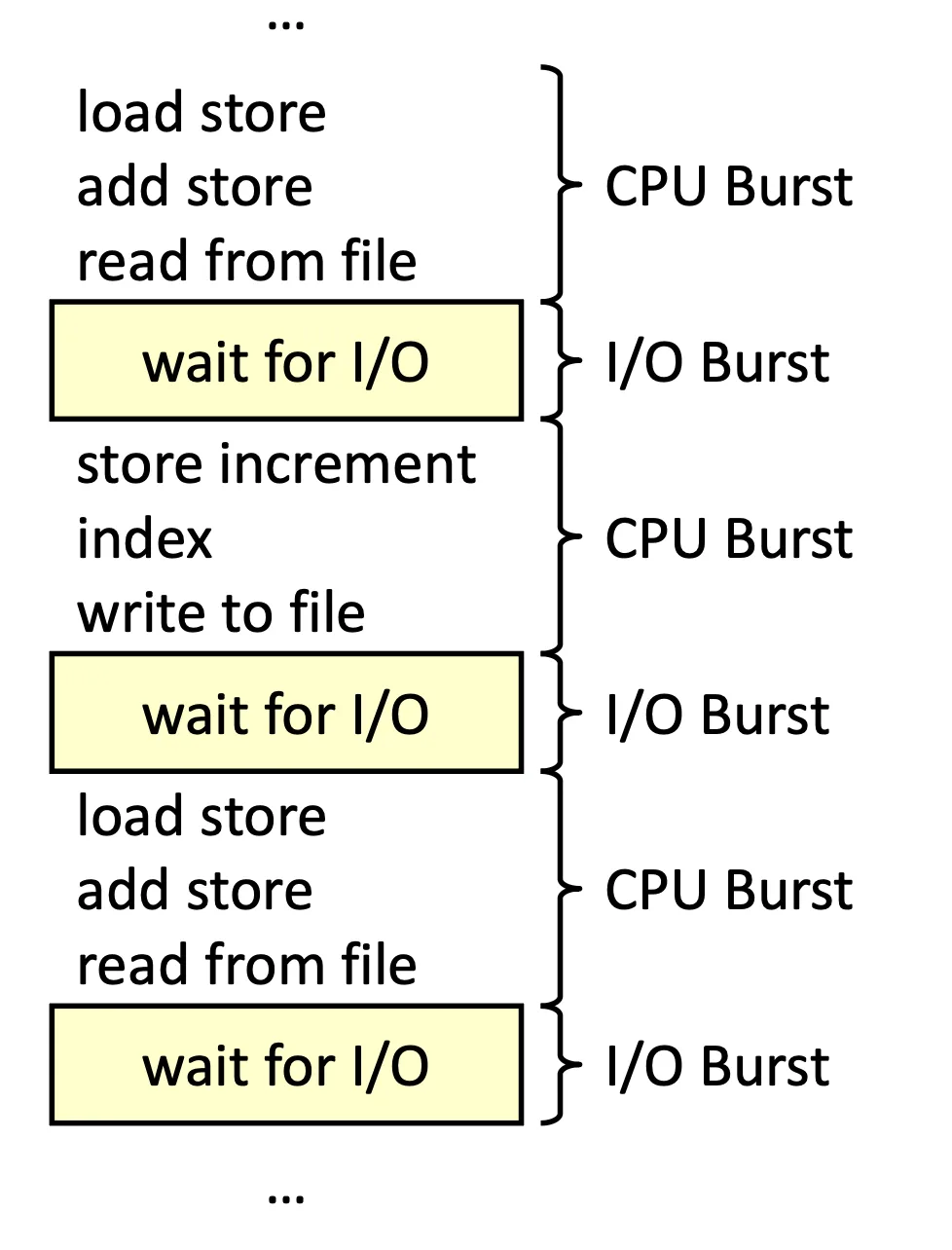
CPU Schedule Concept
我們通常會發現 CPU Burst time 都是非常短的,Distribution 偏小(跟網路封包一樣),根據他們的各自的使用時間,可以分成
- I/O Bound Program
- CPU Bound Program
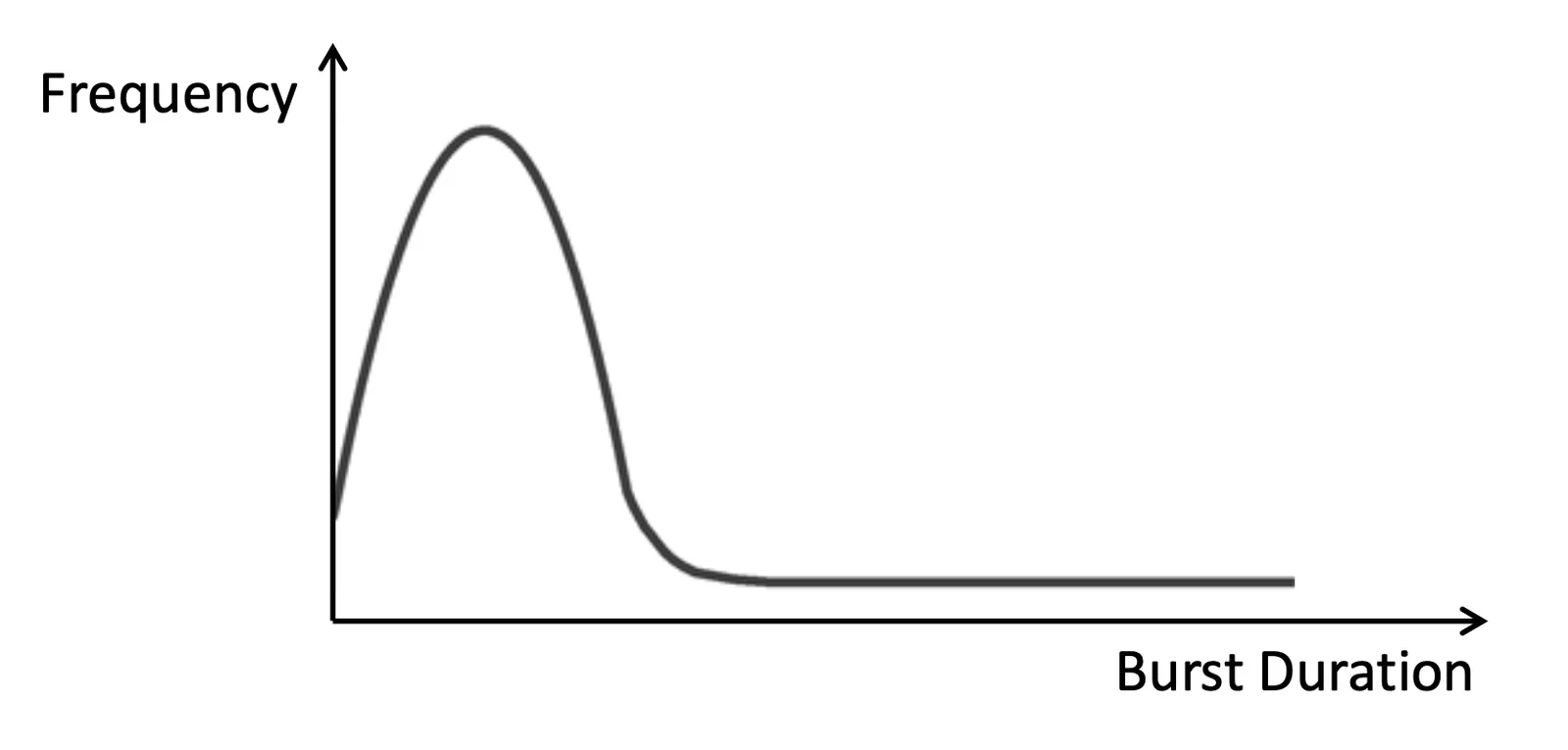
Histogram of CPU Burst time
CPU Scheduler#
CPU Scheduler 主要 focus 在 Ready, Waiting, Running 三個 State 之間的轉換,基本上做的事情就是在四種情況下
- Process 從 Running 到 Waiting
- Process 從 Running 到 Ready
- Process 從 Waiting 到 Ready
- Terminates
如果是 1 or 4 Scheduler 必須從 Ready State 裡面找一個 Process 去 Running State
如果是 2 or 3 系統則有兩種選擇,維持現狀,或是重新抓一個 Process 去 Running
Preemptive and Nonpreemptive Scheduling#
Scheduling 分成兩種
-
Nonpreemptive,就是當任何 Process 回到 Ready State 時,我們不切斷原本正在 Running 的 Process
-
Preemptive,有些在 Waiting 的 Process 有可能是非常重要的 Process 只不過是在等 I/O,等到 I/O 一結束回到 Ready 就要馬上回去 Schedule
大部分現代 OS 大部分是 Preemptive Scheduling,但可能會產生 Race condition,因為有可能產生被 Priority high 的 Process context switch 掉的情況
這個問題會在 Synchronization 的章節解決
Dispatcher#
負責把 Process 分配下去給 CPU run,包含 Context Switch, Switch to User mode 等一系列工作
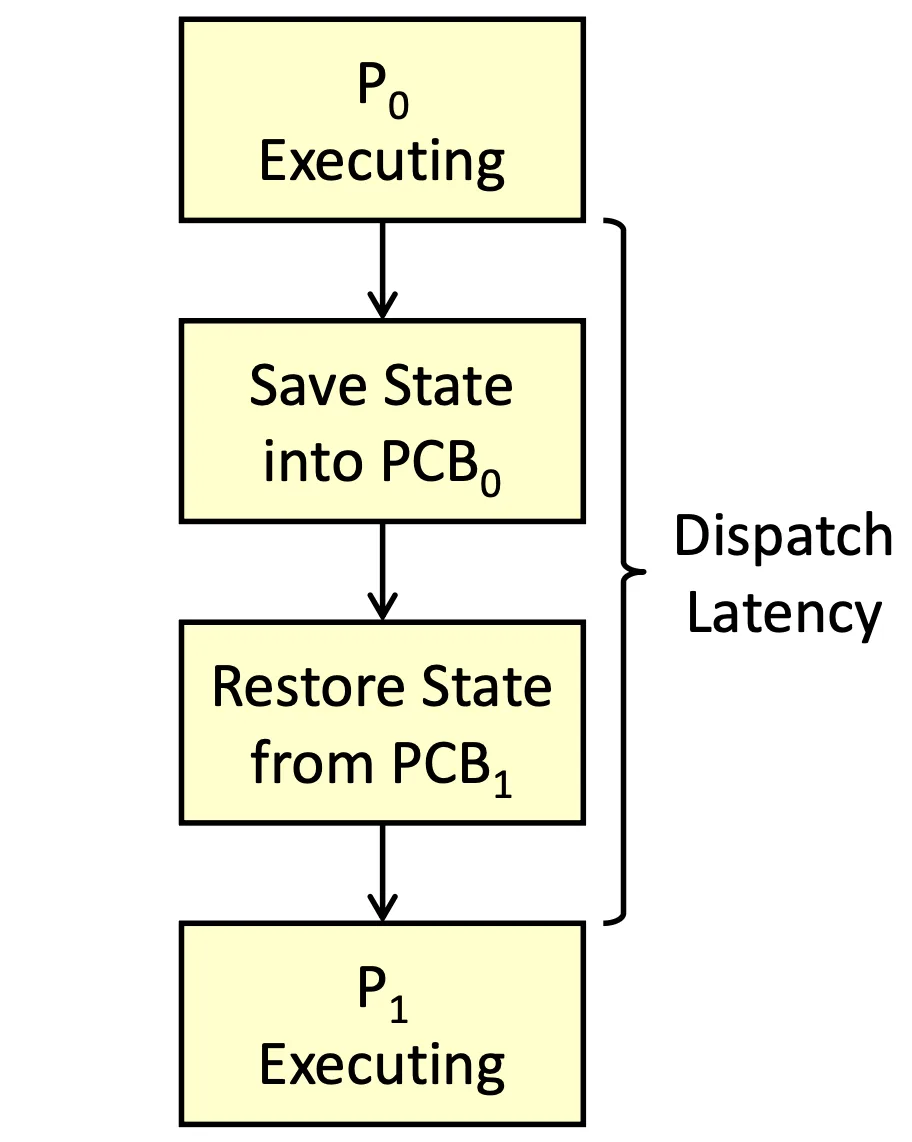
Workflow of Dispatcher
Dispatcher 負責把 CPU 內的資訊存到 PCB 裡面,然後將 CPU 的內容抽換成另一個 PCB 的內容
正在 switch 的過程花的時間我們稱為 Dispatch Latency,是一段 overhead
Scheduling Criteria#
為了要 Optimize 一個 System,我們需要設定一些目標
- Maximize CPU utilization
- Maximize throughput
- Minimize turnaround time:arrival 到執行完畢的時間
- Minimize waiting time:是在 ready queue 裡面等多久
- Minimize response time:從送出 request 到第一次有回應的時間
Scheduling Algorithms#
First-Come, First-Served (FCFS) Scheduling#
| Process | |||
|---|---|---|---|
| Burst Time | 24 | 3 | 3 |
- 假設 arrival order 是 ,我們就可以畫出 Gantt Chart

First-Come, First-Served Scheduling 1
Waiting time 分別是 , average 是
- 接下來假設 arrival order 是 會拿到

First-Come, First-Served Scheduling 2
Waiting time 分別是 , average 是
我們可以觀察到 Convoy effect:所有 process 在等最大的那個 process,所有人都在等他
- one CPU-bound and many I/O-bound processes
Shortest-Job-First (SJF) Scheduling#
如果目標是 minimize waiting time 的話,那 SJF 會是最佳解,簡而言之就是把時間短的工作先做掉
- 如果加上 Preemptive 那會改成 shortest-remaining-time-first
難點是在於我們很難得知後面的 CPU Burst 到底多長,通常得用 estimate 的方式
| Process | ||||
|---|---|---|---|---|
| Burst Time | 6 | 8 | 7 | 3 |

Shortest-Job-First Scheduling
Waiting Time
Prediction of Next CPU Burst#
假設
- : 第 個 CPU Burst 的正確數字
- : 下一個 CPU Burst 的預測
e.g.
| X | 6 | 4 | 6 | 4 | 13 | 13 | 13 | |
|---|---|---|---|---|---|---|---|---|
| 10 | 8 | 6 | 6 | 5 | 9 | 11 | 12 |
- : 固定的預測值
- : 只看最近一次
把公式展開
Shortest-Remaining-Time-First Scheduling#
| Process | ||||
|---|---|---|---|---|
| Arrival Time | 0 | 1 | 2 | 3 |
| Burst Time | 8 | 4 | 9 | 5 |
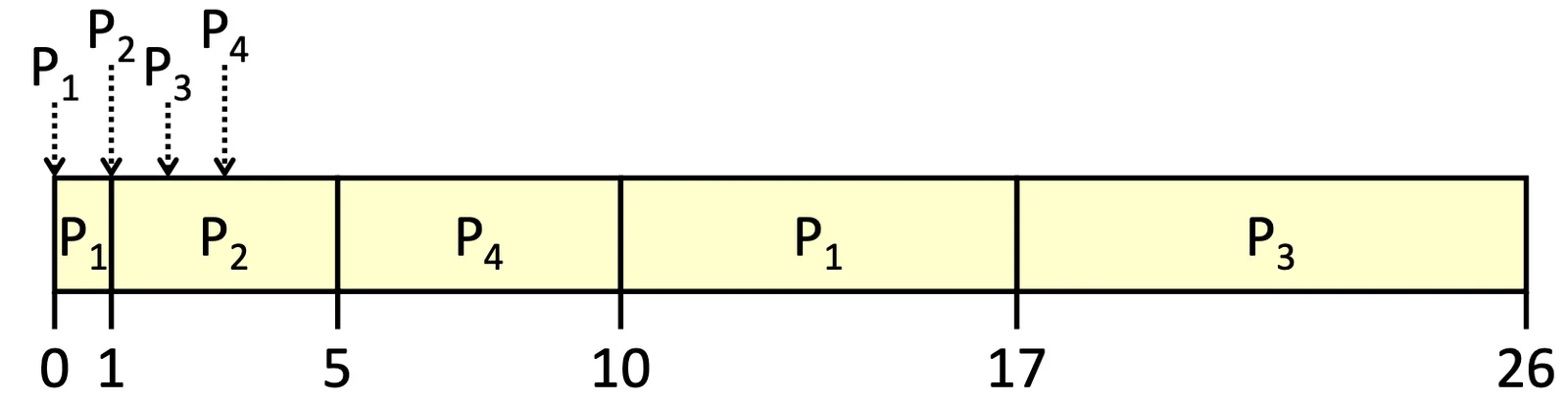
Shortest-Remaining-Time-First Scheduling
如果 Nonpreemptive OS 在這種情況下(arrival time 不一樣),我們的 SJF 不一定會是 Optimal
Round-Robin (RR) Scheduling#
是一種基於「輪流」的演算法,把所有 CPU time 去劃分成很多 time quantum
- 通常是 10~100 msec.
Timer 會在每個 quantum 結束後去做 interrupt 然後 Reschedule
如果現在有 個 process,那每個 process 都會拿到 的 CPU time,而每次最長拿到 time,所以每個 process 最多不會等超過 time
- 如果 很大就變成 FCFS
- 如果 很小理論上很好,會有很好的 response time,但我們還是得考慮 context switch 的 overhead
| Process | |||
|---|---|---|---|
| Burst Time | 24 | 3 | 3 |
Assume
有些 OS 會強制讓 process 把 quantum 用完,即便他結束了

Round-Robin Scheduling
簡單來講,Avg Turnaround time 比 SJF 高,但在 Response time 會比較好
| Process | ||||
|---|---|---|---|---|
| Burst Time | 6 | 3 | 1 | 7 |
80% 的 CPU burst 都會小於 ,所以 Round Robin 就會是一種還不錯的方法,不會讓 Turnaround time 暴增
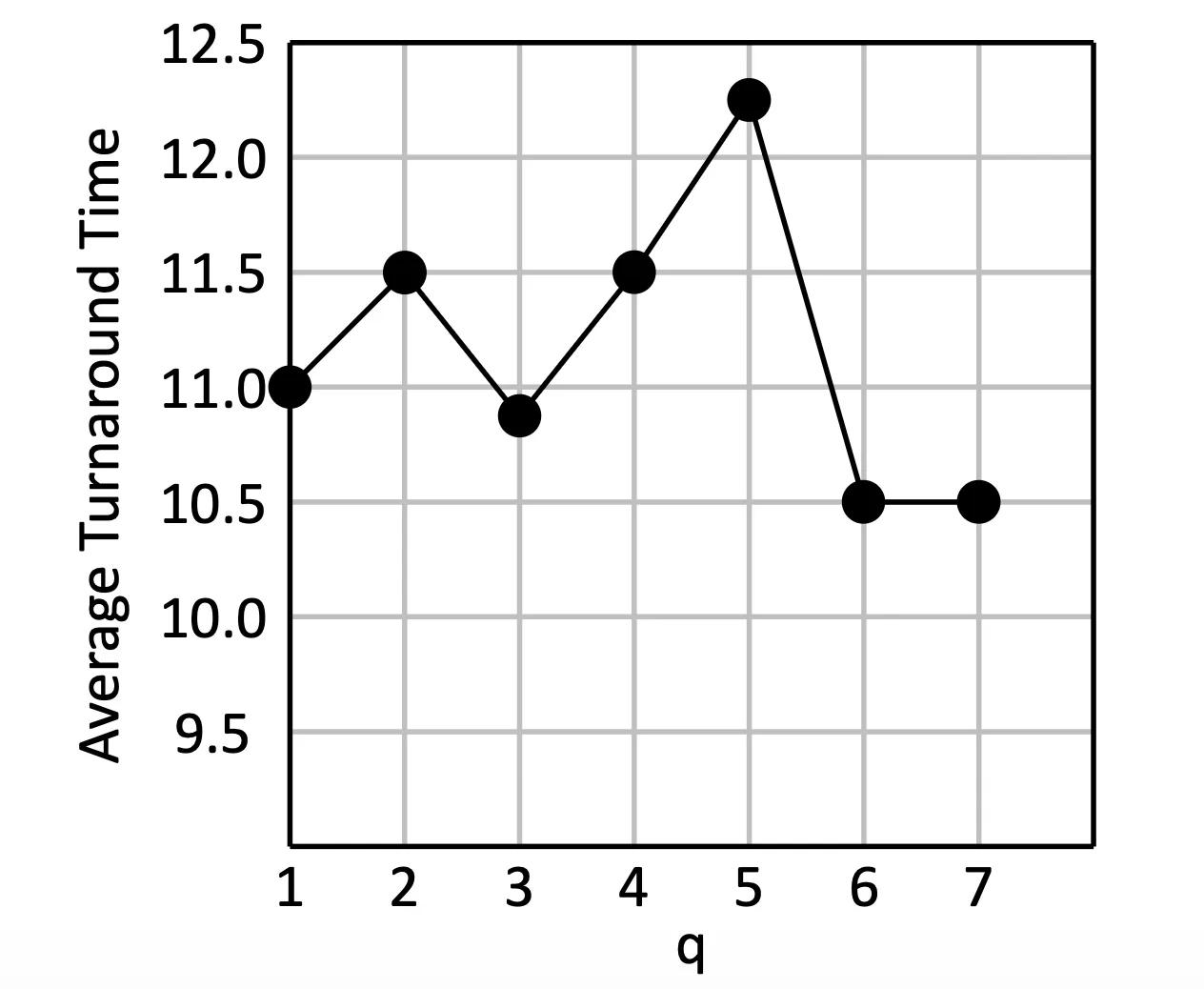
Quantum to Avg Turnaround Time
Priority Scheduling#
SJF 其實也是一種 Priority Scheduling,我們通常講到 Priority 都是
可能會產生 Starvation 的問題,也就是 Priority 低的 Process 完全不可能分配到 CPU time,我們可以用 Aging,也就是根據他存在的時間來提高他的 Priority
| Process | |||||
|---|---|---|---|---|---|
| Burst Time | 10 | 1 | 2 | 1 | 5 |
| Priority | 3 | 1 | 4 | 5 | 2 |
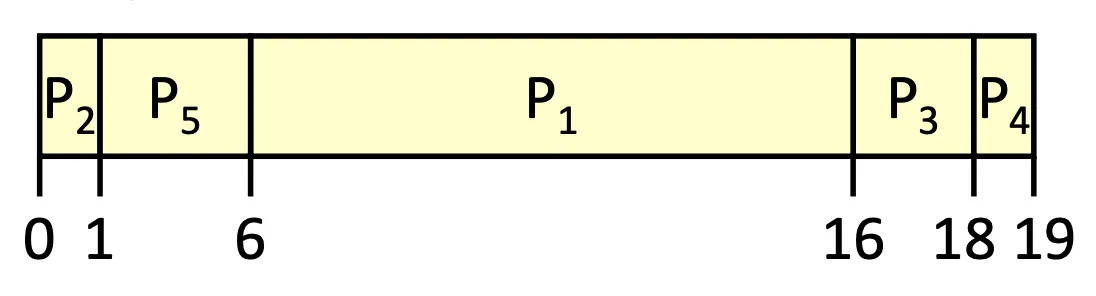
Priority Scheduling
Waiting time:
通常我們如果都做了 Priority,Avg time 的 Criteria 就應該考慮其他項目,比如果 Priority 高的項目的 response time
Priority Scheduling with Round-Robin#
| Process | |||||
|---|---|---|---|---|---|
| Burst Time | 4 | 5 | 8 | 7 | 3 |
| Priority | 3 | 2 | 2 | 1 | 3 |
Time Quantum

Priority Scheduling with Round-Robin
基本上就是先以 Priority 做排序,如果一樣就用 Round Robin 做輪換
Multilevel Queue Scheduling#
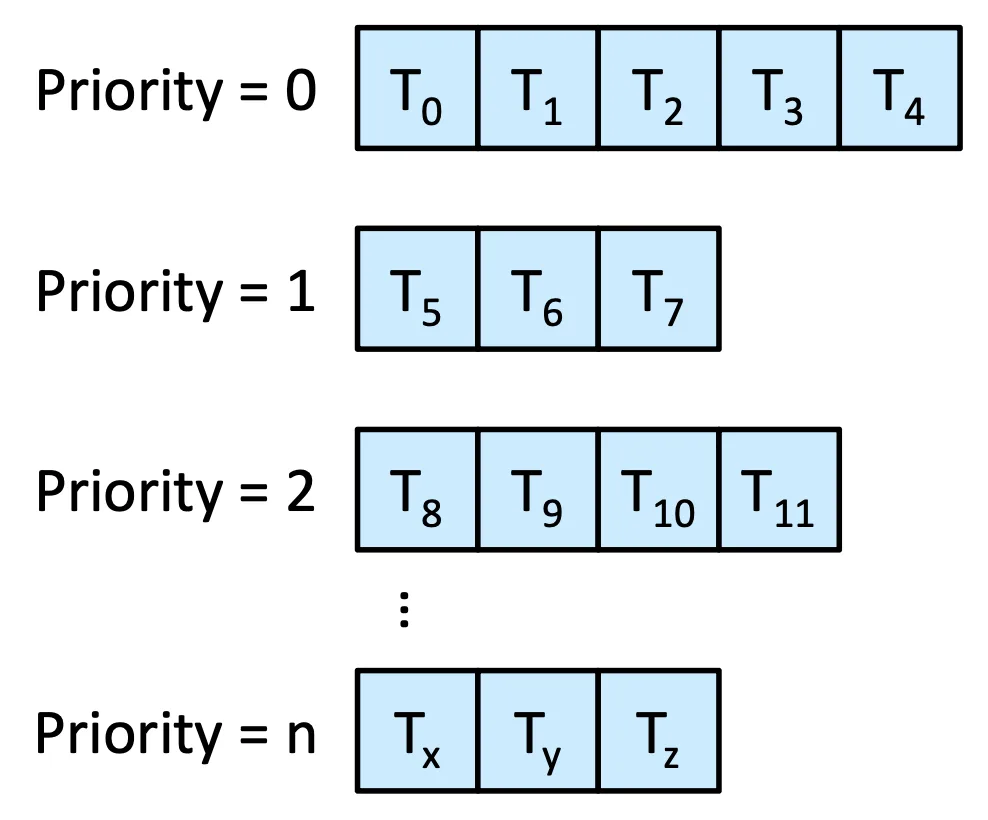
Multilevel Queue
一次直接選一整個 Queue,先執行最高 Priority 的 Queue
以下是一個真實案例,每個 Queue 可以有自己的 Schedule Algorithm
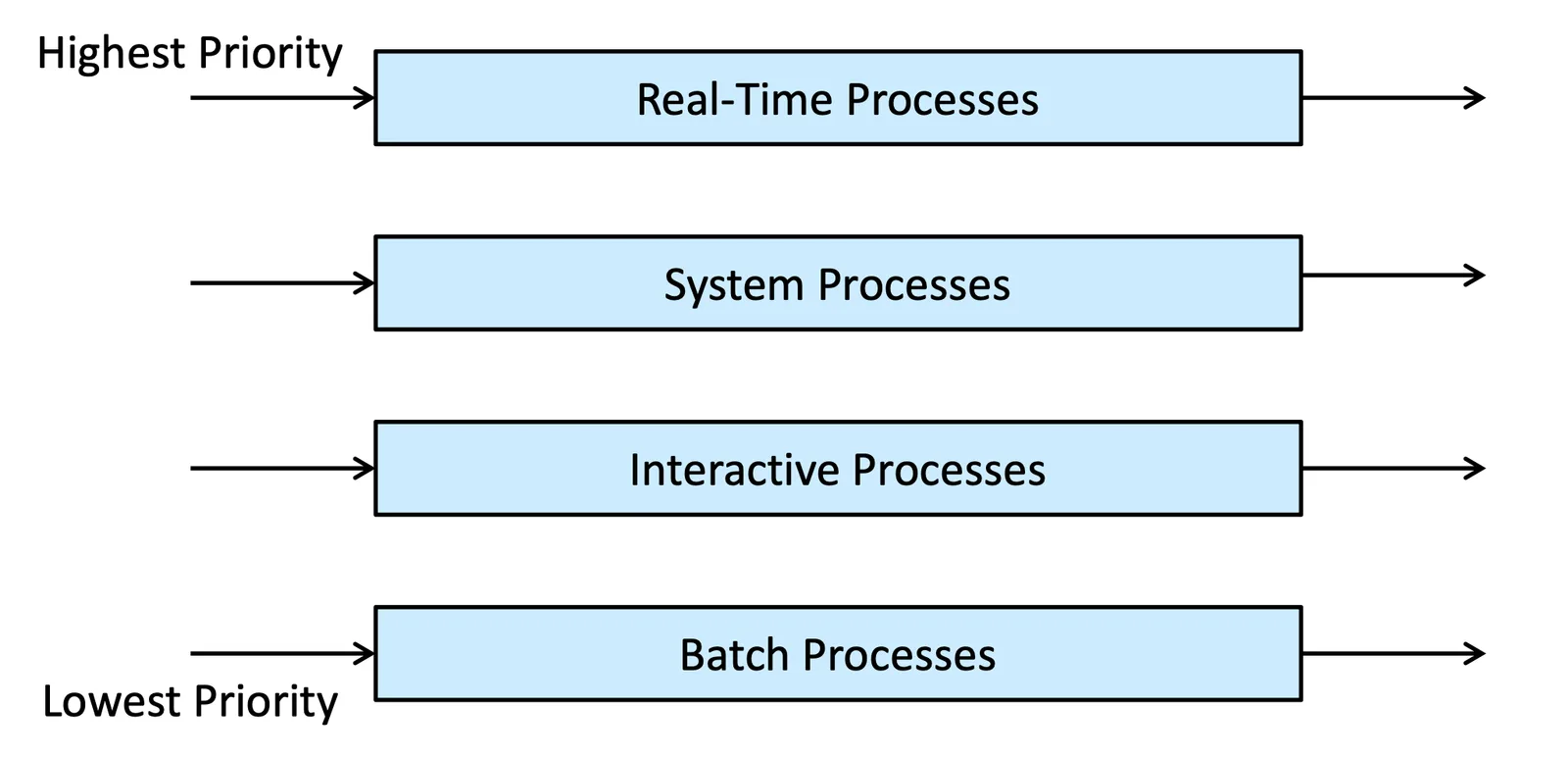
Multilevel Queue Scheduling
- Real-time Process:代表他是有自己的 Deadline 的 process
- System Process:維持基本系統功能的 process
- Interactive Process:有互動式介面,要時不時去 Check Output/Input
- Batch Process:單純的運算
Multilevel Feedback Queue Scheduling#
一個 Process 本來在某個 queue,但可能會在執行過程中發生變換,Priority 會有變動
- Aging 就可以用這種 mechanism 實現
以下是一個實際例子
- :RR with time quantum 8 milliseconds
- :RR with time quantum 16 milliseconds
- :FCFS
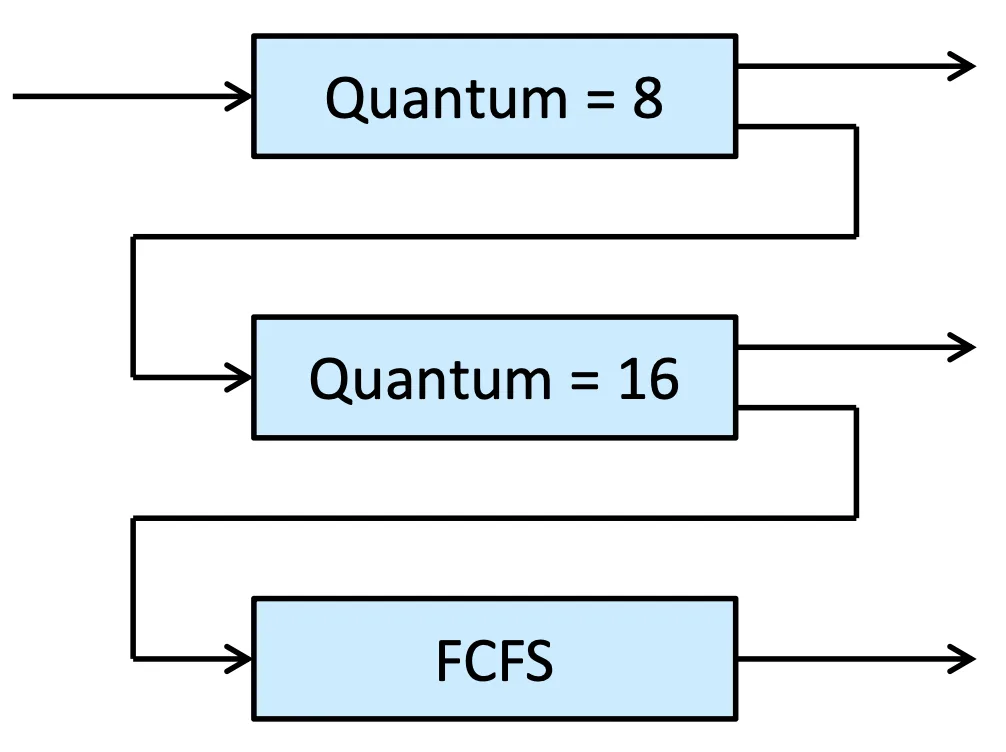
Multilevel Queue
- 如果一個 Process 先進到 ,用 RR 做 schedule,在 1 個 quantum (8 ms) 內沒做完的話,我們就放到 內
- 進到 ,用 RR 做 schedule,在 1 個 quantum (16 ms) 內沒做完的話,我們就放到 內
- 在 內做 FCFS
Thread Scheduling#
我們現在講 Scheduling,其實在現代 OS 上都是在排 Kernel Thread,基本概念跟 Process Scheduling 一樣,而 User-level Thread 都會用 LWP 去做 Mapping,把 User Thread Map 到 Kernel Thread 上
Contention Scope#
分成 Process-contention scope (PCS), System-contention scope (SCS)
- Process-contention scope (PCS):當 Model 是 many-to-one 或是 many-to-many,會產生同一個 process 內的 thread 自我競爭,通常會讓 Programmer 自行排定 Priority
- System-contention scope (SCS):全系統上的競爭,Thread Scheduling 可能會需要考慮全系統的 Thread,比如說 one-to-one model
Pthread Scheduling#
PTHREAD_SCOPE_PROCESSPCS schedulingPTHREAD_SCOPE_SYSTEMSCS scheduling
Linux and macOS only allow
PTHREAD_SCOPE_SYSTEM
以下是設定的方法 pthread_attr_getscope()
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[]) {
int i, scope;
pthread_t tid[NUM_THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* first inquire on the current scope */
if (pthread_attr_getscope(&attr, &scope) != 0)
fprintf(stderr, "Unable to get scheduling scope\n");
else {
if (scope == PTHREAD_SCOPE_PROCESS)
printf("PTHREAD_SCOPE_PROCESS");
else if (scope == PTHREAD_SCOPE_SYSTEM)
printf("PTHREAD_SCOPE_SYSTEM");
else
fprintf(stderr, "Illegal scope value.\n");
}
/* set the scheduling algorithm to PCS or SCS */
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i], &attr, runner, NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread_exit(0);
}Multi-Processor Scheduling#
現代的系統通常是 multi-core,所以 Schedule 會變成一個更複雜的問題,需要考慮 Locality 的問題,並且有很多種 Architecture
- Multicore CPUs
- Multithreaded cores
- NUMA systems
- Heterogeneous multiprocessing
Approaches to Multiple-Processor Scheduling#
當要做 Schedule 的時候我們分成 Symmetric 跟 Asymmetric
-
Asymmetric Multiprocessing: 存在一個 Master 管控所有 Processor,讓他去做真正的 Schedule,這樣簡單,但是 Master Processor 就會非常忙碌,I/O event 會特別的多
- 在 embedding system 比較常見
-
Symmetric Multiprocessing (SMP): 每個 Processor 都是同等地位,每個 Processor 要自己去處理自己的 Schedule 問題,從 Queue 裡面拿出 task,可以分成兩種
- 共用 Queue,有彈性,但需要處理 Race Condition (需要 Locking)
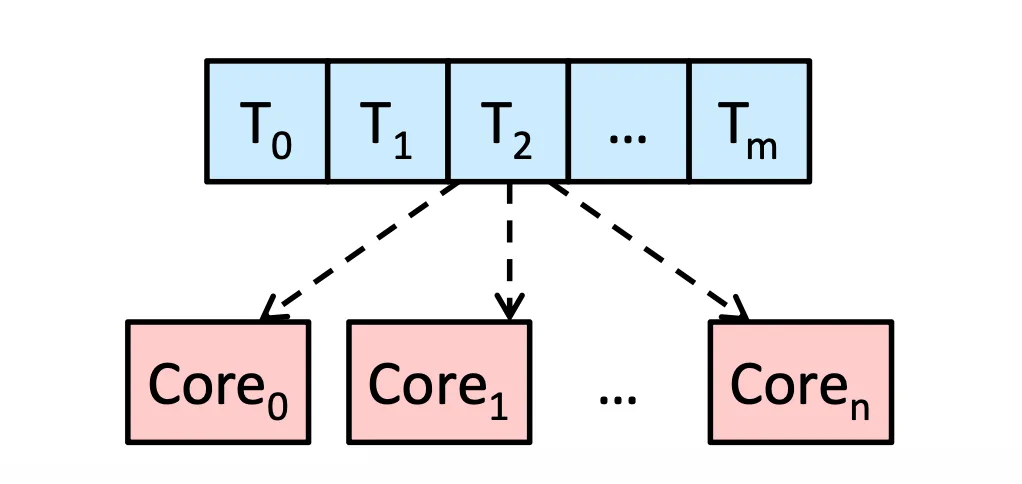
Share Queue
- 分開 Queue,需要做 Load Balancing
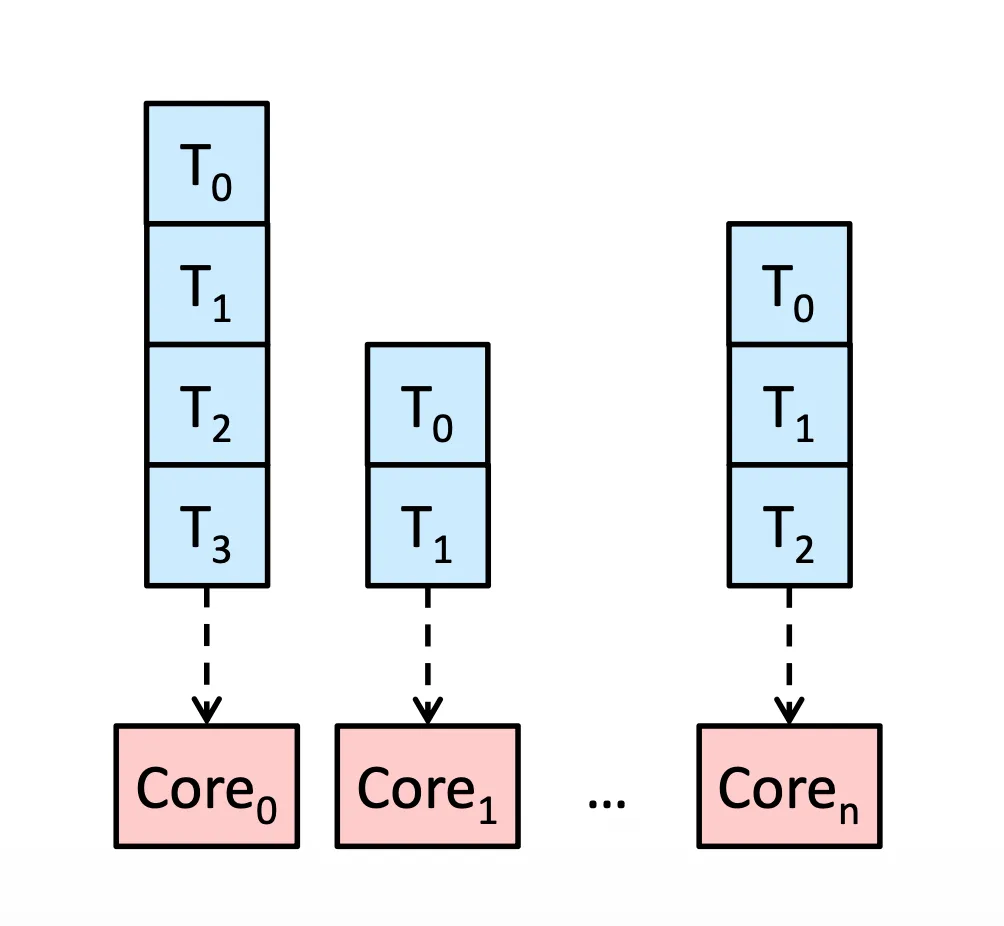
Separate Queue
Multicore Processors#
是一種趨勢,每個 core 本來就支援超過一個 Hardware Thread 在同一個 core 上執行,是一種 Hardware 等級的加速
因為 core 在執行一個 thread 的時候一定會需要 memory stall 也就是需要去讀取 memory,就會需要暫停一下,為了增加效率,我們可以讓 thread 做交替的 Compute, Memory Stall,就可以達成加速
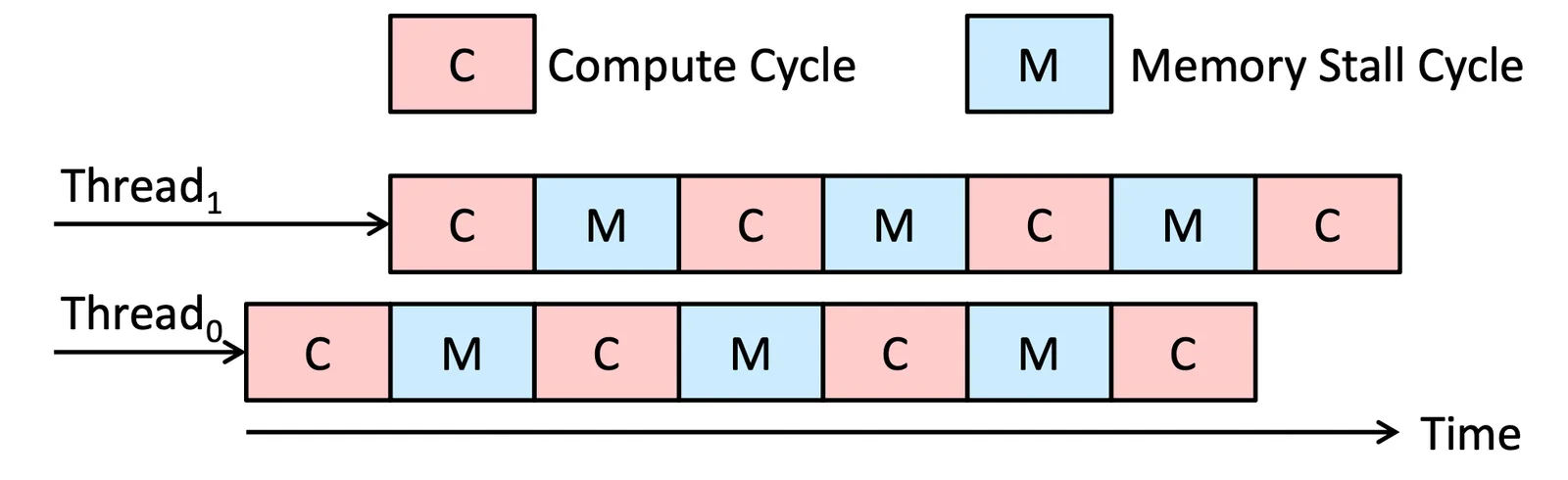
Multicore Processors
在 OS 層面上他其實不在乎有多少個 Core 在執行我的 Process,或是硬體 implement 的方法,系統通常會做 Virtualization,也就是把真正的硬體,轉化成一個 OS 比較看得懂的形式
- 真正的把 CPU 對應到 Core 上的 Thread 我們是用 Chip multithreading (CMT) 來分配,在 Intel 裡面叫做 hyper-threading
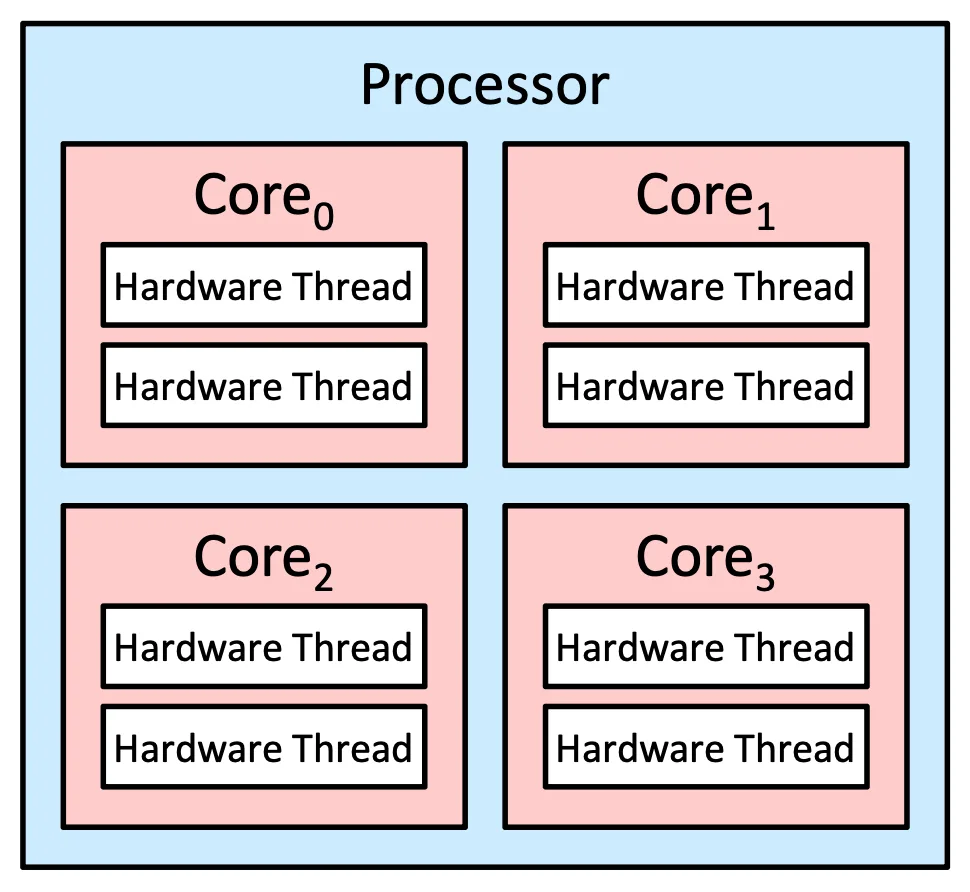
Multithreaded Multicore System
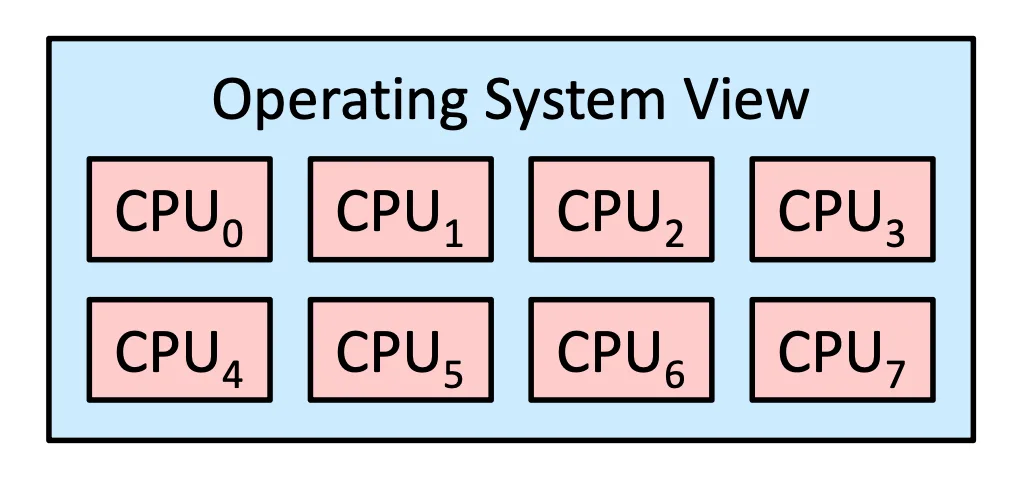
OS view of Multithreaded Multicore System
Threading 有各種 Thread: User, Kernel, Hardware,我們會做 2 level threading 來實現
- User Thread,我們通常只會接觸這個,用 LWP 接到 Logical processor 上
- 在用第二層的 Schedule 把它弄到真正的 core 上
這樣兩層式的 Scheduling 如果完全切開,那就有可能會把最佳解給切掉,所以我們設計的時候通常會把東西不切得那麼死,這些 thread 不會 mutually exclusive,完全切開的話就是簡單,有時候也是一種好事(有時候如果 level 之間可以有一些 communication 或是 knowledge 就可以讓 performance 變好)
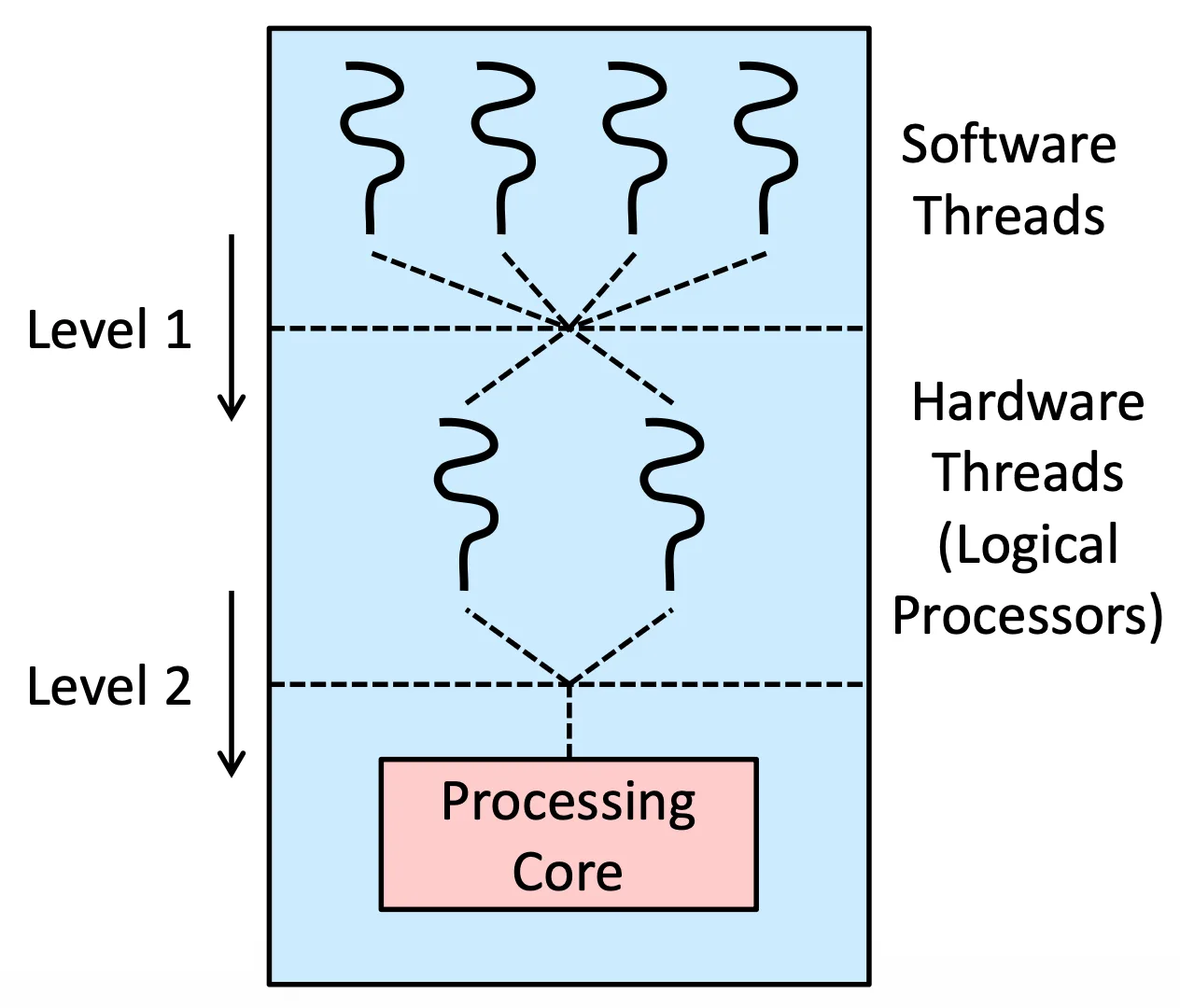
Two level Threading
Load Balancing#
在一個 SMP 系統裡面,我們希望可以平衡每個 core 的 loading,這裡只有很 high level 都講而已,這些方法其實都可以做數學證明保證
-
Push Migration: 每個 processor 上有一個 task 專門去看現在是不是工作分配不均,如果發現的時候,就把多的任務推出去
-
Pull Migration: 空的 processor 去把別人的 task 拉過來
Processor Affinity#
Affinity 是親和力的意思,看看 process 有沒有自己偏好的 core
e.g. 有一個 thread 本來在一個 core 上,那執行相關 data 的 thread 理應要跑在那個 core 上
我們可以分成兩種 Affinity
- Soft affinity: 不強迫,processor 可以拒絕,那就 schedule 到其他 core 上
- Hard affinity: 強迫他到那個 processor 上,可能是 security 的問題,在車子上可能有很多 CPU 但某些 task 一定要指定 CPU,因為車子通常是不做 scheduling 的,東西都是週期性的
NUMA and CPU Scheduling#
如果一個 system 是 NUMA-aware,那 memory 的地位就不一樣了,需要考慮 Processor Affinity
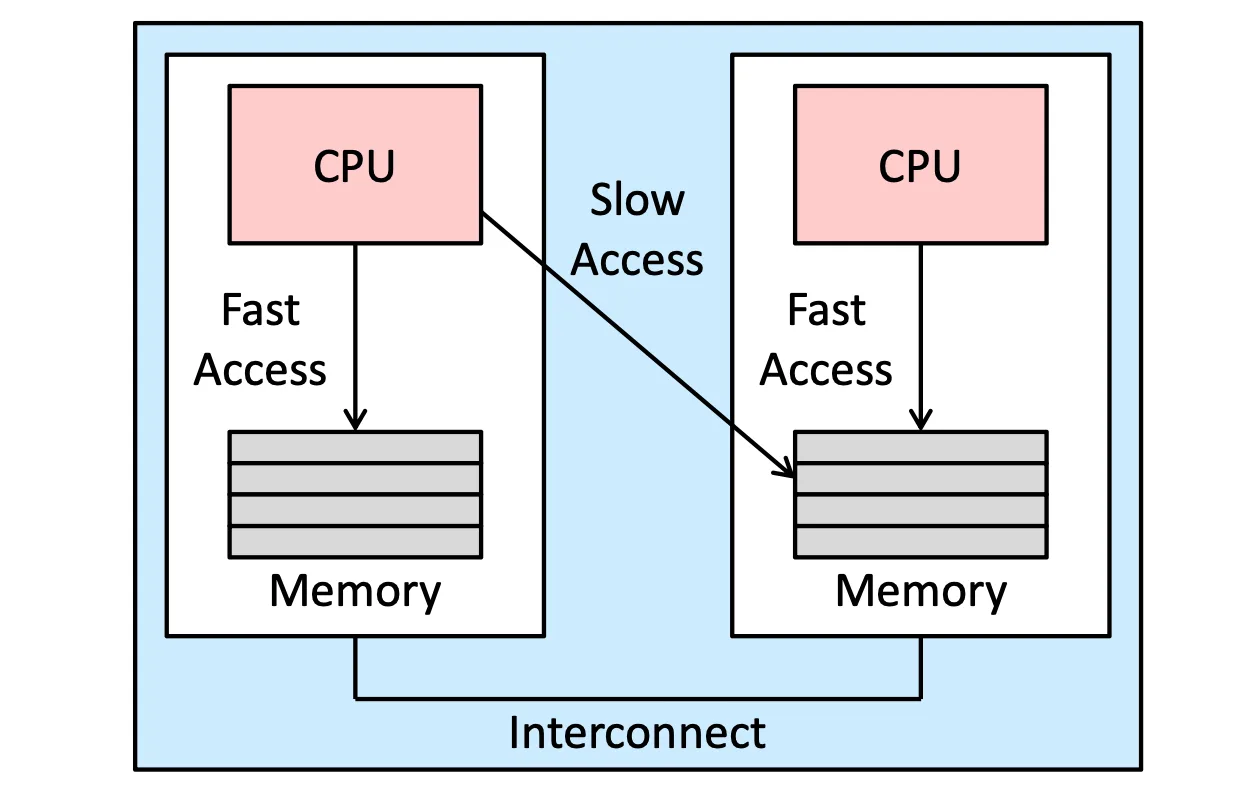
NUMA (Non-Uniform Memory Access) System
Heterogeneous Multiprocessing (HMP)#
在 ARM 架構下,有一個 big.LITTLE 架構,可以根據 task priority 或是 mode 去做選擇
- Big cores:耗能,但算得很快
- Little cores:用的能量少,做日常工作
Real-Time CPU Scheduling#
在做 realtime scheduling 的時候我們會引入 deadline 的概念
- Soft real-time systems:有保證 Critical real-time tasks 會比別人先做,但並不保證 deadline 前做完
- Hard real-time systems:保證在 deadline 前必須做完
一般我們用的電腦沒有需要使用到 real-time,通常是用在汽車、醫療系統上
Minimizing Latency#
定義 Event latency:從發生時間,到被 system response 的時間
這裡的 reponse time 跟普通 system 的 response time 不太一樣,因為 real-time system 的 response time 是必須要 process 處理完畢並且做出反應才算完成的,而普通 system 的 response time 是從送出 request 到第一次有回應的時間(讓你不會覺得系統卡住)
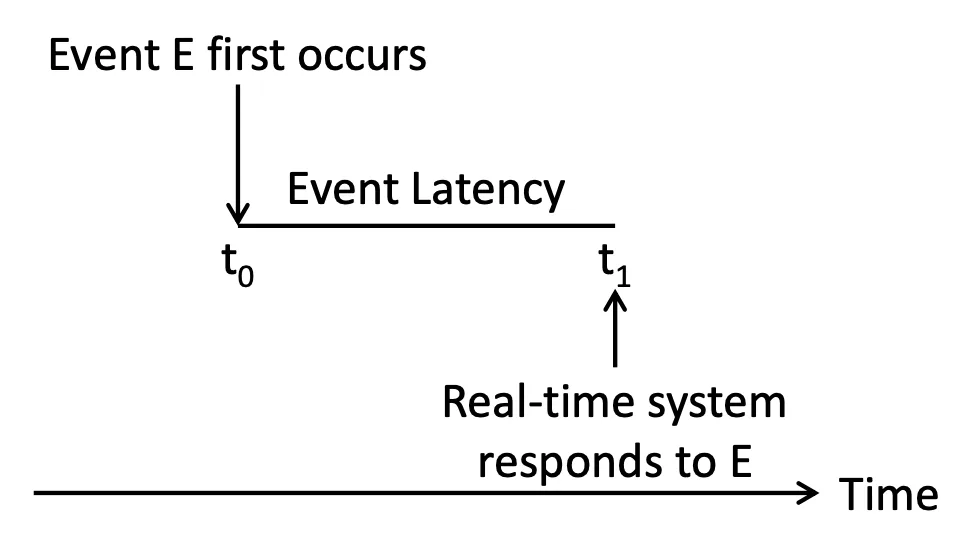
Event latency
通常有兩種 latency 會影響到 Event latency
- Interrupt latency
- Dispatch latency
Interrupt Latency#
Interrupt 到的時間,一直到開始跑 ISR(Interrupt Service Routine)的時間,因為需要花時間決定哪個 Routine 來 handle 這個 interrupt
real time system 我們會希望這個時間短
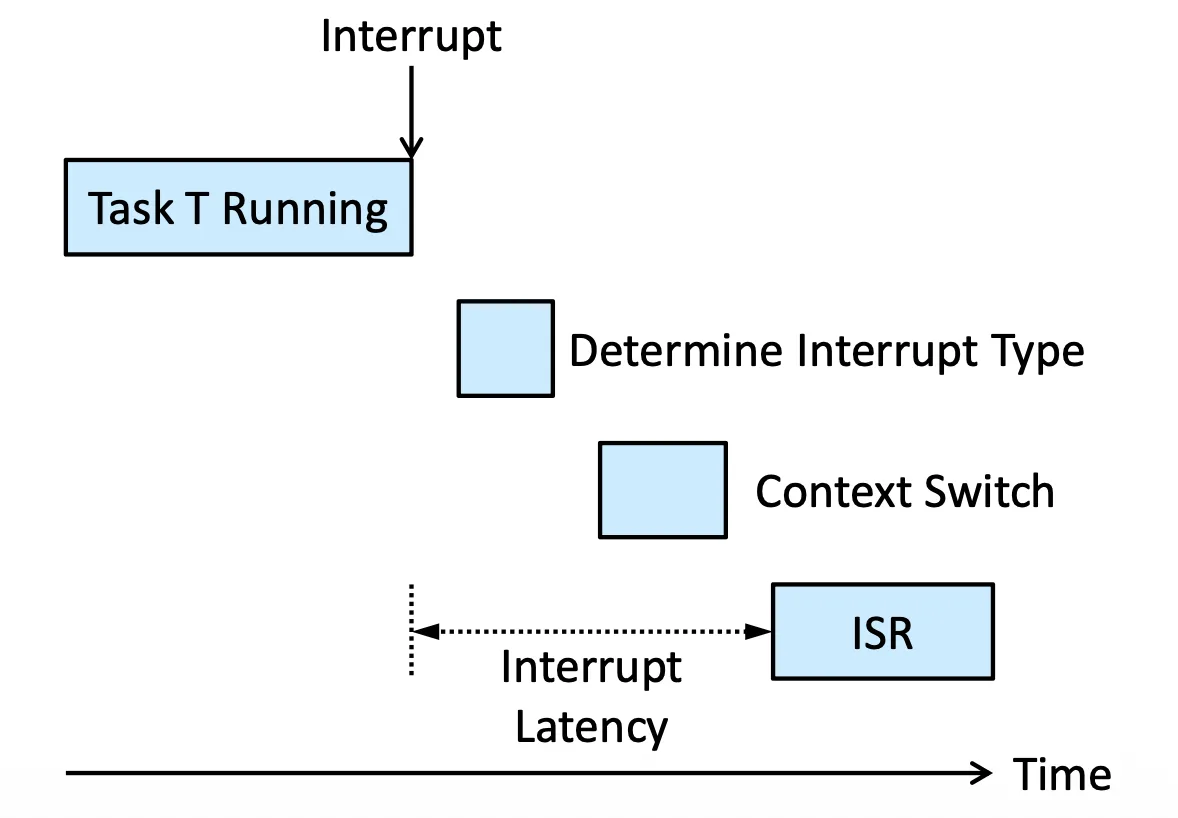
Interrupt Latency
Dispatch Latency#
我們需要把 Core 上的 Process 轉換成另外一個 Process 來跑,要把資源 release 出來
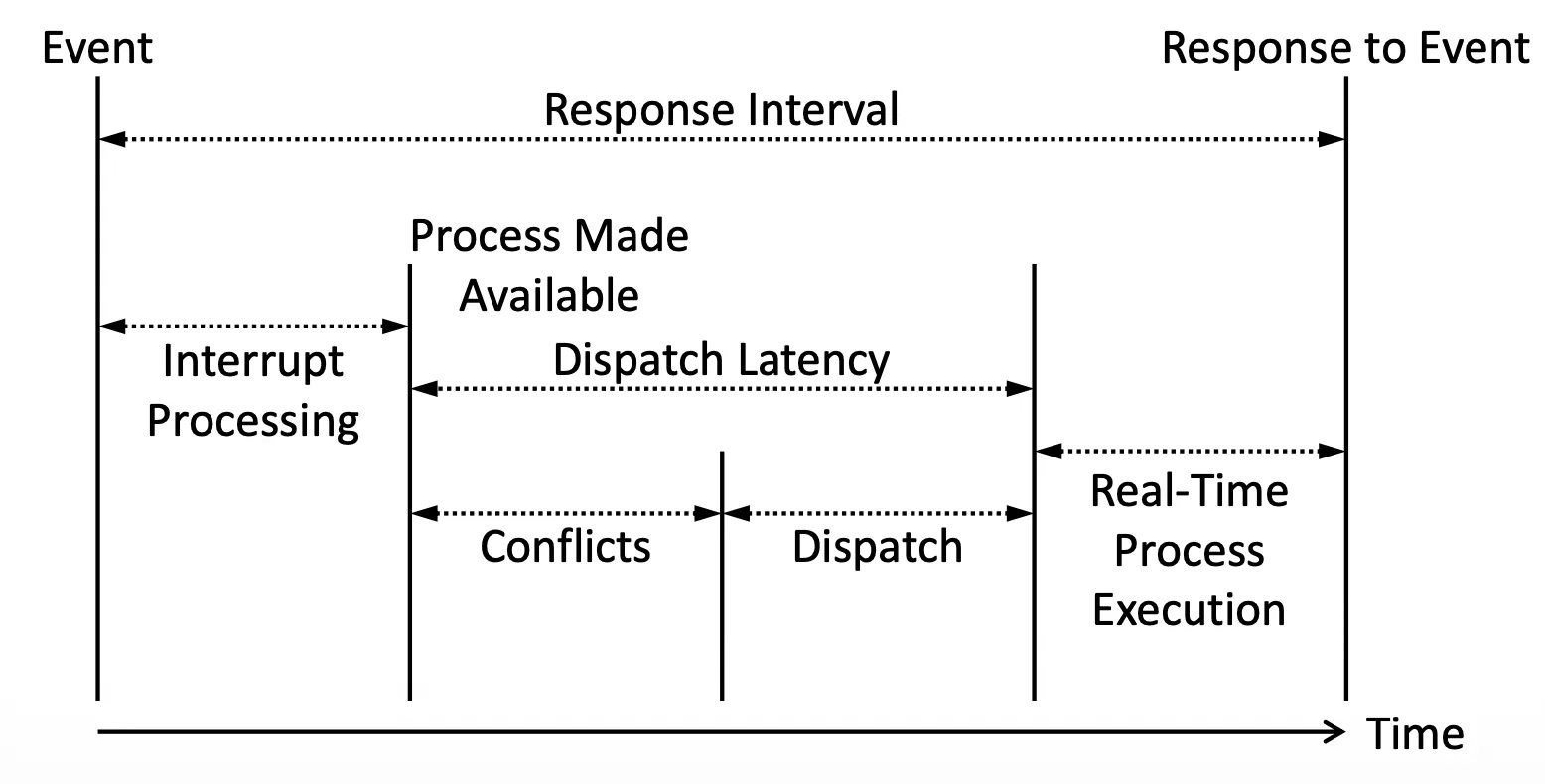
Dispatch Latency
其實看圖可以知道,後面還有 Real-Time Process Execution 佔了大宗的 Response time,但這其實是 Application 該處理的部分
Interrupt Processing 其實又可以分成 Interrupt Latency 跟 ISR Processing
Priority-Based Scheduling#
跟之前的 Priority Scheduling 是一樣的,我們給他一個 Priority,但是,如果我們只給他一個 Priority 我們不能保證他必定 meet deadline
我們還需要做一些數學分析,才能知道能不能在 deadline 內處理完
現在這種 model 我們需要考慮 periodic 的 Process
- Processing time =
- Deadline =
- Period =
- Rate of periodic task is
在真實世界 realtime system 需要處理的 task 通常都是週期性的,如果不是週期性,我們很難做到 real time
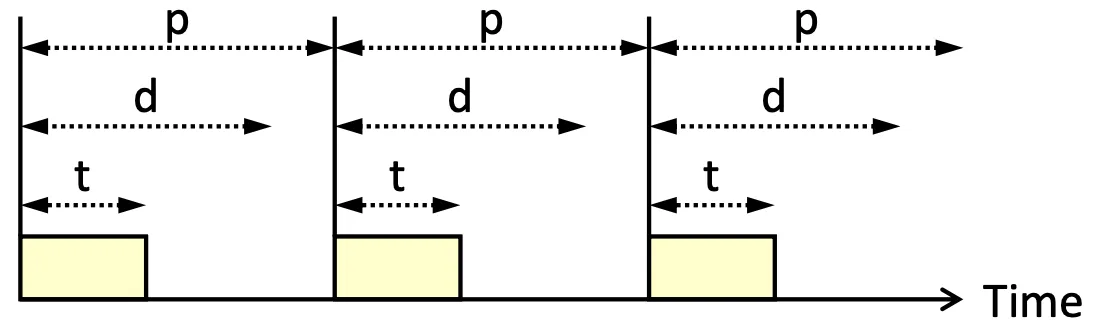
Periodic Process require CPU at constant interval
Rate-Monotonic Scheduling#
其實也是一種 Priority Scheduling,每個 task 進來我們用 Period 做 Priority,因為通常週期越短 deadline 也越短,而且通常 deadline 會小於 Period(甚至通常都是一樣的),因為在後一個 Instance 進來前我們就要做完前面一個
假設我們有一個 Preemptive System
| Process | ||
|---|---|---|
| 20 | 35 | |
| (= ) | 50 | 100 |
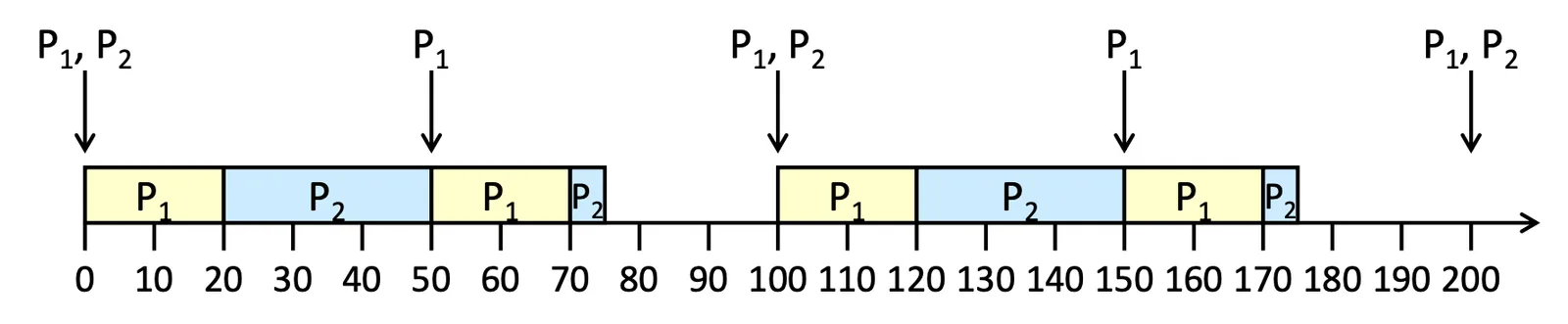
Example of Rate-Monotonic Scheduling
, 都在 deadline 前做完了
現在這裡有一個反例,明明可以滿足,但 Rate-Monotonic 失敗了
| Process | ||
|---|---|---|
| 25 | 35 | |
| (= ) | 50 | 80 |
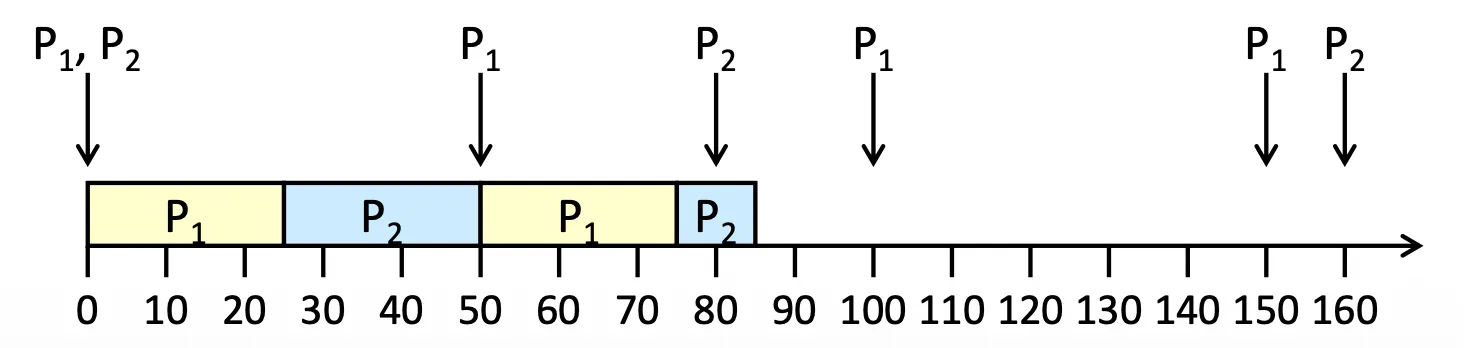
Counter-example of Rate-Monotonic Scheduling
雖然 都可以符合,但 失敗了,但其實明明就可以 fulfill,只要不 Preempt
Earliest-Deadline-First (EDF) Scheduling#
從名字就可以看出來,他一定是最佳解,但是 trade-off 也最高,把 deadline 早的那個設成高 Priority
| Process | ||
|---|---|---|
| 25 | 35 | |
| (= ) | 50 | 80 |
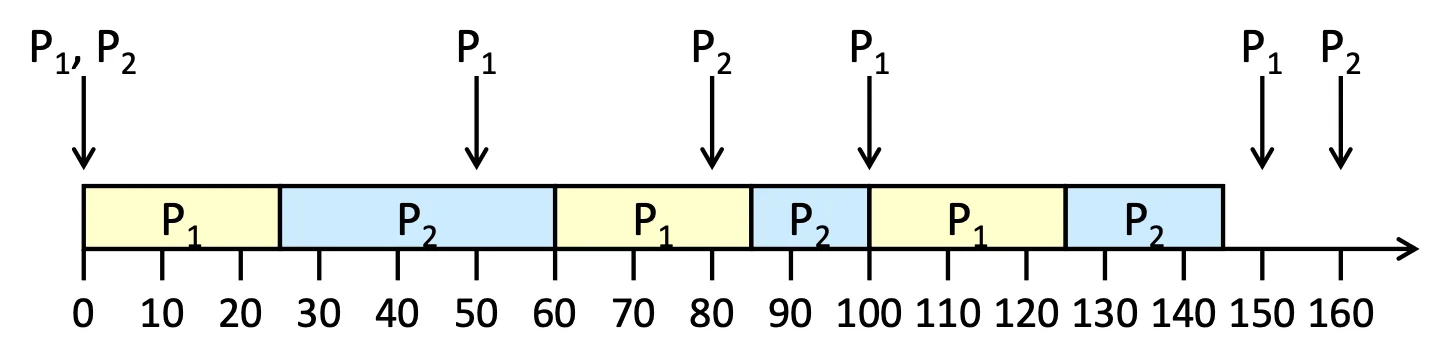
Example of EDF Scheduling
在第 50 秒的時候, 第一個 instance 的 Priority 是高於 的,所以不會被打斷 在第 100 秒的時, 第二個 instance 的 Priority 低於 所以被打斷
Proportional Share Scheduling#
把 CPU 的運算時間,分成很多個小的 interval,保證分給某個 Task 某些數量的 interval,是一種 guarantee
假設 是所有 Process share 的時間,Process 可以 share 到 ,也就是可以保證每個 Process 收到 的 Time interval
假設 , 分別有 ,如果有個 想進來,只要他 就會被 admission controller 拒絕掉這個要求,因爲他不是照比例分的,而是時間保底,在 real-time system 裡面,我們做了數學分析,如果 要做,我們保證他可以分到某個數量,那麼 worst case 就是可控的
POSIX Real-Time Scheduling#
POSIX 上有兩種建立在 Priority Base 的 Implementation
SCHED_FIFOSCHED_RR
以下兩個指令可以控制
pthread_attr_getschedpolicy(pthread_attr_t *attr, int *policy)pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy)
以下是範例 code
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[])
{
int i, policy;
pthread_t tid[NUM_THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* get the current scheduling policy */
if (pthread_attr_getschedpolicy(&attr, &policy) != 0)
fprintf(stderr, "Unable to get policy.\n");
else {
if (policy == SCHED_OTHER) printf("SCHED_OTHER\n");
else if (policy == SCHED_RR) printf("SCHED_RR\n");
else if (policy == SCHED_FIFO) printf("SCHED_FIFO\n");
}
/* set the scheduling policy - FIFO, RR, or OTHER */
if (pthread_attr_setschedpolicy(&attr, SCHED_FIFO) != 0)
fprintf(stderr, "Unable to set policy.\n");
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread_exit(0);
}Operating-System Examples#
Linux Scheduling#
早期的 Linux Scheduling 是 time,但是後來覺得應該要更優化,時間變長,但效果更好
現代採用的是 Completely Fair Scheduler (CFS),是一種 Priority Base,把 task 分出 scheduling classes
- Default Scheduling
- Real-Time Scheduling
Default Scheduling#
沒有直接把 Priority 定死,有兩個參數影響
- nice value:
-20 ~ +19越大代表越容易讓 core,會牽扯到 targeted latency,也就是在某段時間內一定要給這個 task 跑一次,是可能會變動的 - virtual run time:
vruntime可以控制預估的 Burst time,也可以根據過去的經驗變動
Real-Time Scheduling#
根據 POSIX.1b 來規定,會把 Default Scheduling class 的 nice value map 到 100 ~ 139
Linux NUMA-Aware Load Balancing#
可以讓同一個 thread 的工作都被放在同一個 domain 裡面運作
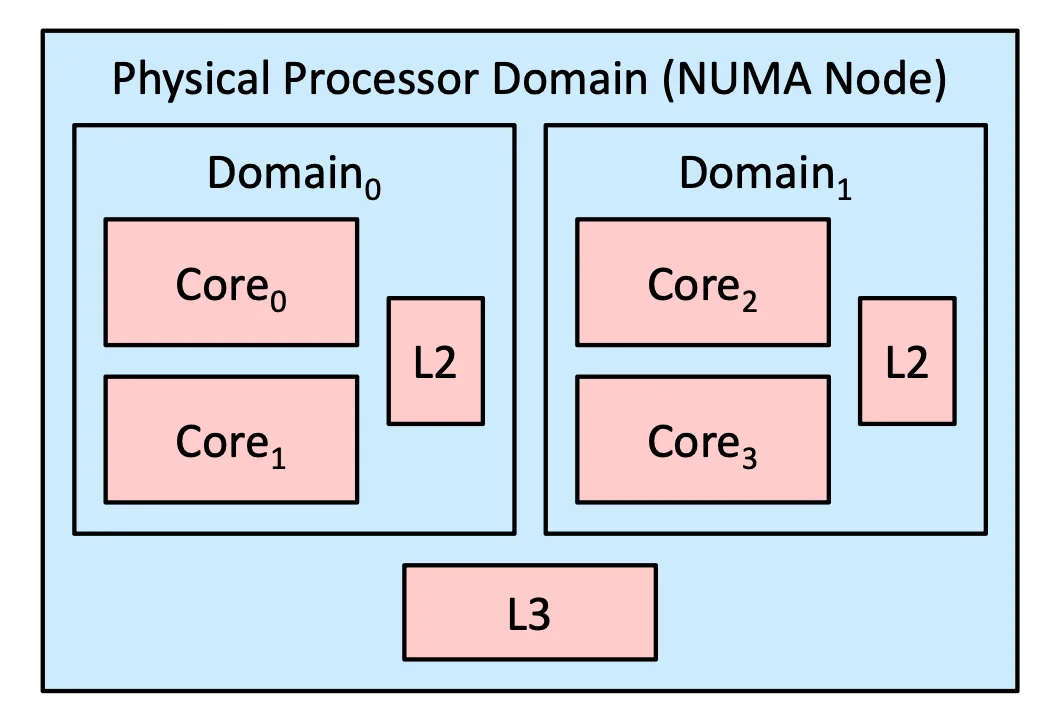
Example of domain
Windows scheduling#
也是 Priority base,有一個 dispatcher 負責,有很多種 class,variable class 是 1 to 15,real-time class 是 16 to 31
每個 thread 都有 class REALTIME_PRIORITY_CLASS, HIGH_PRIORITY_CLASS, ABOVE_NORMAL_PRIORITY_CLASS, NORMAL_PRIORITY_CLASS, BELOW_NORMAL_PRIORITY_CLASS, IDLE_PRIORITY_CLASS
並且他們在裡面還有再細分 TIME_CRITICAL, HIGHEST, ABOVE_NORMAL, NORMAL, BELOW_NORMAL, LOWEST, IDLE
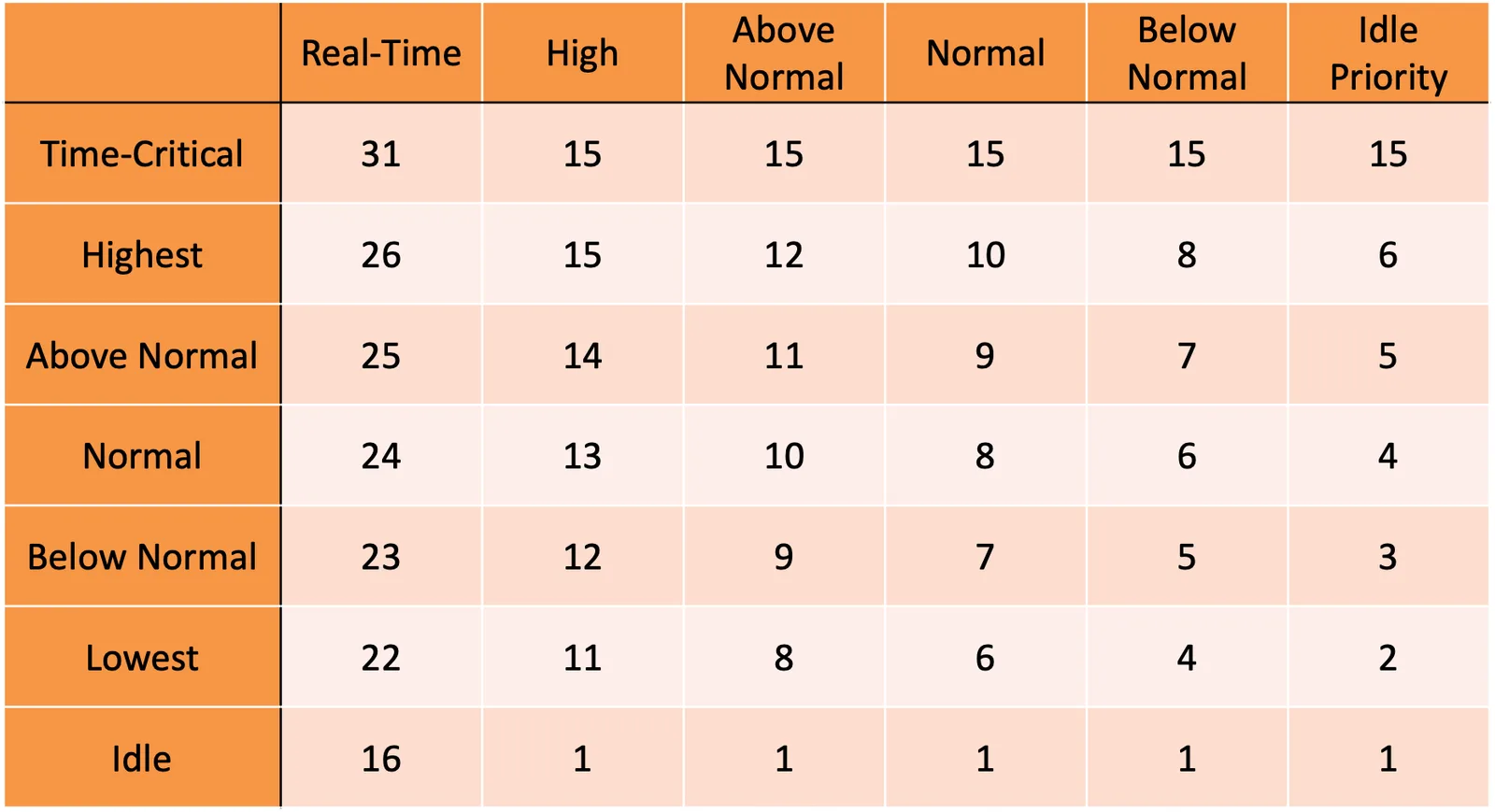
Windows scheduling
Real-time IDLE 還是比剩下的高
如果被放到 foreground,那通常他的 scheduling quantum(時間配額)會被乘以 3,Win7 有提供 user-mode scheduling (UMS)
Solaris scheduling#
用 RR,也分 class
- Real time (RT)
- System (SYS)
- Fair share (FSS)
- Fixed priority (FP)
- Time sharing (TS)
- Interactive (IA)
也細分,Time Sharing 跟 Interactive,當 expired 的時候,分到的 Priority 會變化
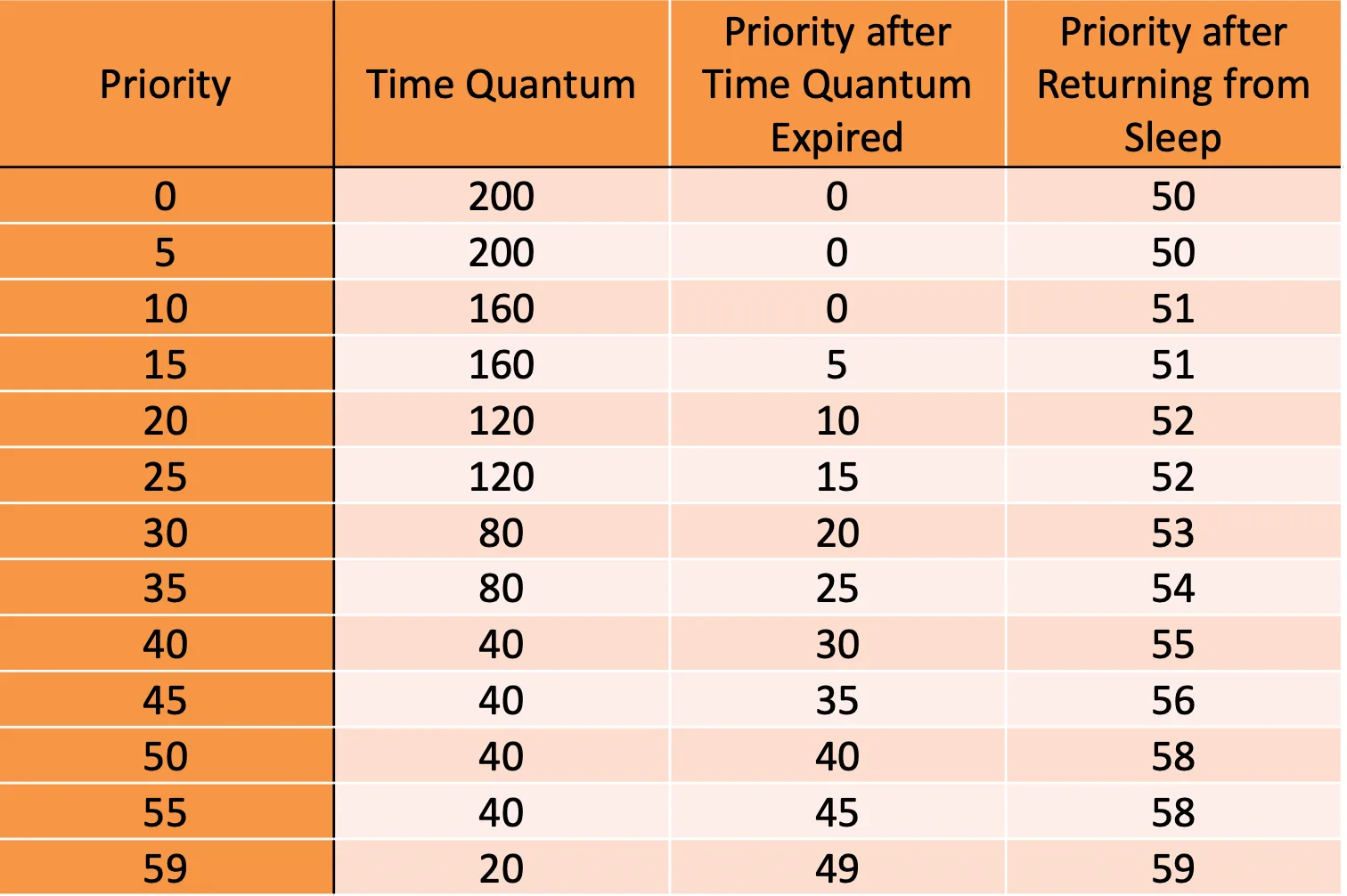
Solaris scheduling
在 Solaris 裡面 Priority 數字越高,代表 Priority 越高
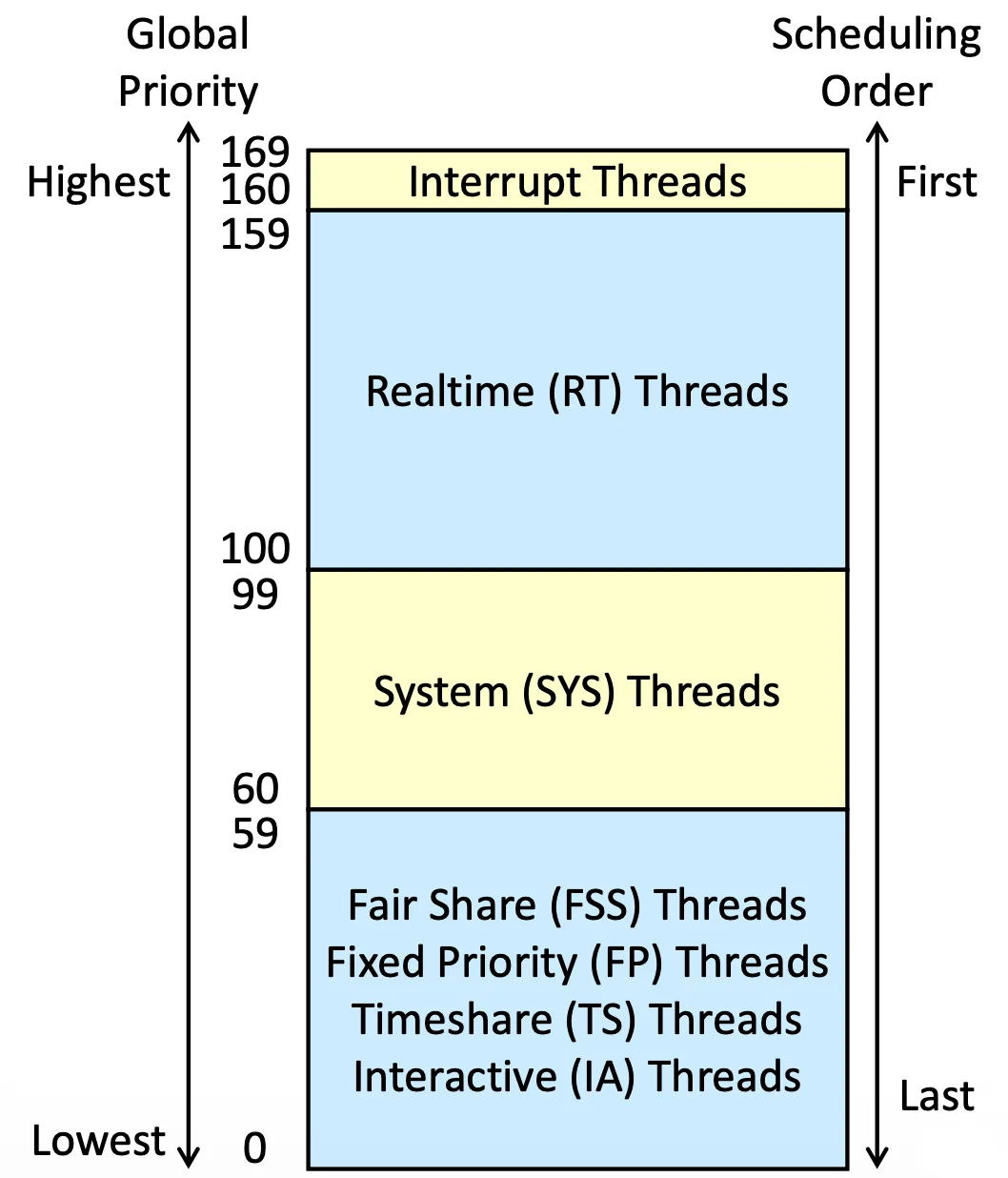
Solaris Priority
Algorithm Evaluation#
我們一樣得先想好要用什麼 criteria,不同系統需要的東西不一樣
Deterministic Modeling#
直接用實際例子去跑
| Process | |||||
|---|---|---|---|---|---|
| Arrival time | 0 | 0 | 0 | 0 | 0 |
| Burst Time | 10 | 29 | 3 | 7 | 12 |
假設我們要 minimize avg waiting time

FCFS:28ms

Nonpreemptive SJF:13ms

Round Robin:23ms
這種方法只能判斷出每個 input 的結論,沒辦法給出全局結果
Queueing Models#
我們用機率模型去描述一個 CPU 到底是怎麼運行的,也就是用 Queuing Theory 來做分析,這是另外一門課,會涉及到 Markov Process 之類的 model
Simulations#
採用一個大量測資,以量來模擬,用過去機率分布來決定,就是根據實際的資料去跑 Deterministic Modeling,用平均決定
但 simulation 終究沒辦法保證有數學上的 Worst case,通常用數學 close form 表示都會比較悲觀
Implementation#
我們直接把它 implement 到一個 system 上面測試,但這樣會非常高風險、高成本,而且真實的環境有很大的波動