Mass-Storage System#
Overview#
Hard Disk Drives (HDDs)#
磁碟上的一片一片叫做 platter 可以存資料,一圈叫一個 track, track 裡面一段一段就是 sector,把不同層的 track 組合在一起我們叫他 cylinder
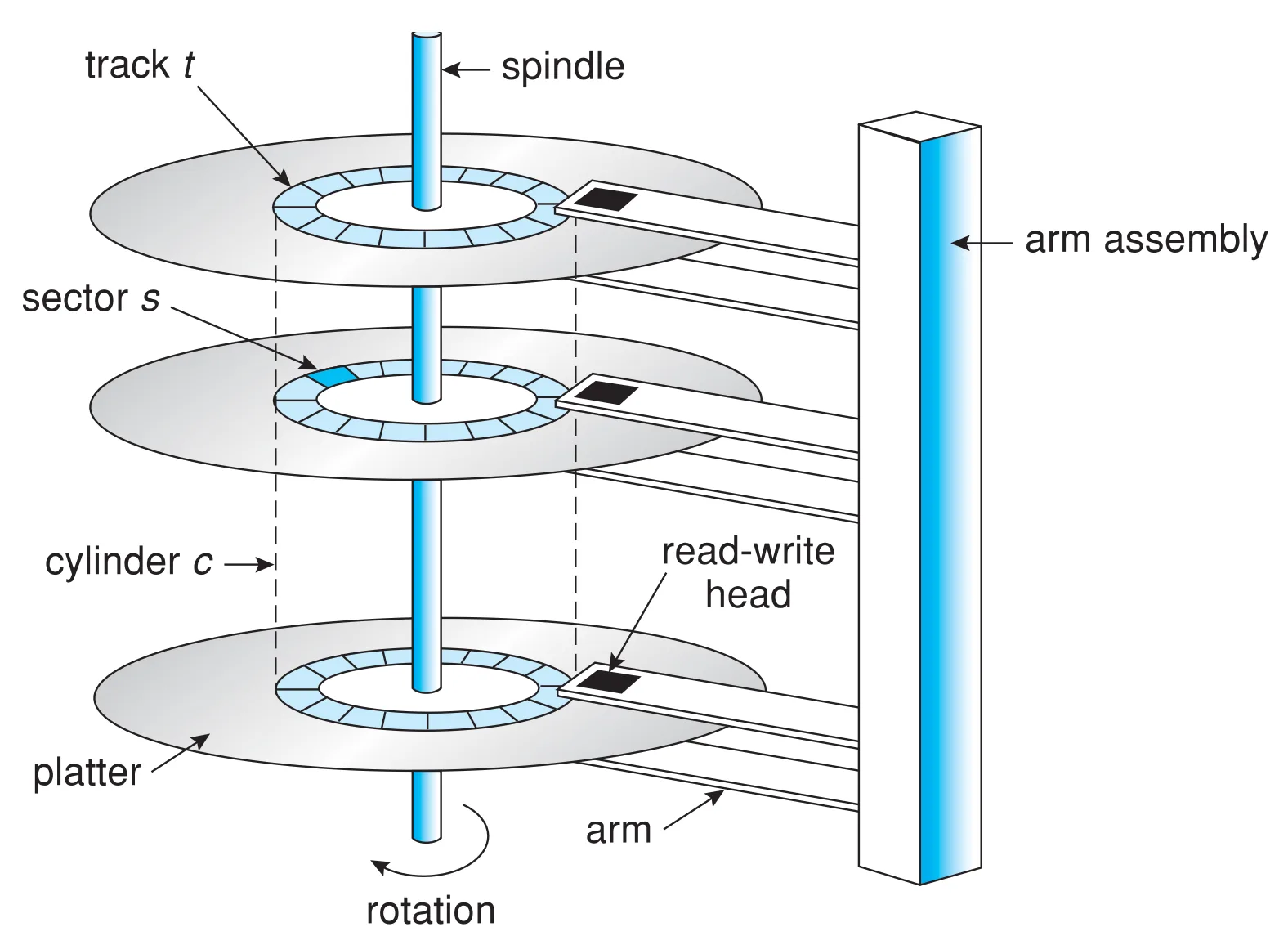
Hard Disk Drives (HDDs)
HDD Performance#
現在的 HDD 每分鐘會旋轉 5000~15000 RPM
- Transfer rate Data 在 Drive 跟 Computer 之間傳輸的速度
- Positioning time (Random-access time)
- Seek time: Disk arm 控制他的長度跑到指定 cylinder 的時間
- Rotational Latency: 旋轉到正確 sector 的時間
- Head crash: Disk Head 跟 platter 直接碰到了(不好)
額外定義幾個名詞
- Access time:
- I/O time:
Nonvolatile Memory (NVM)#
USB drive 就是一種,NVM 常常被當作一種 disk-drive like container,我們也叫他 Solid-state Disk (SSD)
- Pros: 相較於 HDD 是比較 reliable 的,因為 HDD 是物理上機械式行為,並且會比較快
- Cons: 缺點就是容量比較小而且比較貴
有一點值得注意是 NVM device 通常沒辦法跟傳統 bus 搭配,因為傳統 bus 是設計給 HDD 的,硬湊可能會產生很大的 bottleneck
SSD 因為自己的特性,雖然也是用 page 存取,但沒辦法 overwrite,要先做 erase,這個 erase 的動作一次都是一個 block 也就是好多個 page,因此會產生很大的 overhead,並且 SSD 有一個 erase 的次數上限,大概 100,000 次的複寫就不能夠再繼續存資料了
所以我們常常用 drive writes per day (DWPD) 來衡量一個 SSD 的 life span
NAND Flash Controller Algorithms#
在沒有 Erase 的情況下,NAND Flash 沒辦法直接 Overwrite。因此,當我們要更新同一筆資料時,只能把它寫到另一個乾淨的空白 address,這會導致舊 address 的資料變成 Invalid 為了解決資料位置不斷改變的問題,我們需要 Flash Translation Layer (FTL) 來維護一張映射表,追蹤每筆邏輯資料目前實際存放的實體位址。
隨著寫入次數增加,Invalid data 會散佈在各個 Block 中浪費空間,這時就需要 Garbage Collection (GC) 來回收空間。GC 會挑選出包含大量 Invalid data 的舊 Block,把裡面剩下的 Valid data 搬移到新的空白 Block 中,接著把舊 Block 整個抹除 Erase
為了確保 GC 運作時,永遠有多餘的空白 Block,SSD controller 會保留一部分使用者看不到的隱藏容量,這稱為 Overprovisioning (OP)。
此外,因為每個 Block 都有壽命限制,控制器還會執行 Wear Leveling 演算法,主動將資料搬移分配,讓所有 Block 的抹除次數盡可能平均,藉此延長整顆 Flash 的壽命
Others#
Volatile Memory#
其實可以把 RAM 當作一個 Drive,用一樣的方法操作他,像是 Linux 中的 /dev/ram 但這樣的資料關掉之後也是會消失
不用 cache 或 buffer 的原因是因為這些地方空間有限,OS 需要這些空間。
這是一種 temporary storage 在 Linux 裡面也可以存在 /tmp 用 tmpfs 的 file type,速度當然會比較快
Connection Method#
所有 secondary storage 都會有各自跟 computer 連接的方法,各自有各自的 feature
- Advanced technology attachment (ATA)
- Serial ATA (SATA)
- eSATA
- Serial attached SCSI (SAS)
- Universal serial bus (USB)
- Fibre channel (FC)
- NVM express (NVMe) especially for NVM devices which are much faster than HDDs
而這裡也有 Controller 的概念:
- host controller: 在電腦端負責用 message 傳指令給 device controller
- device controller: 在 device 端用自己的 cache 接收指令
- controller 跟 storage device 本身有資料的傳輸
- controller 跟 host 的 DRAM 也會有 DMA 的連接
Address Mapping#
通常會把一個 storage device 視為一個 one dimension arrays,我們叫他 logical blocks,這是一個 smallest unit of transfer
我們可以把它 map 到實體的 device 上面
logical block address 會讓我們比較好處理,一樣是種 virtualization 的操作
- Constant linear velocity (CLV): 內圈外圈的 sector 一樣大
- Constant angular velocity (CAV): 每圈 sector 一樣多
HDD Scheduling#
OS 需要負責讓硬體的 Access time minimize 以及 Bandwidth maximize,也就是 seek time 跟 rotational latency
當一個 Process 需要執行 I/O 都要發給 OS 一個 system call,會提供以下資訊
- input or output
- open file handle (
fd) - memory address for the transfer
- The amount of data to transfer
OS 提供的 queuing request 機制可以讓 device optimize performance
我們要真正知道 HDDs 的 head 在哪是非常困難的,但我們可以做一些估計
- LBA 越大通常 physical address 越大
- LBA 相近的 block 通常 physical block 也會有 proximity
FCFS Scheduling#
假設
- Request queue:
98,183,37,122,14,124,65,67 - Head pointer 在
53
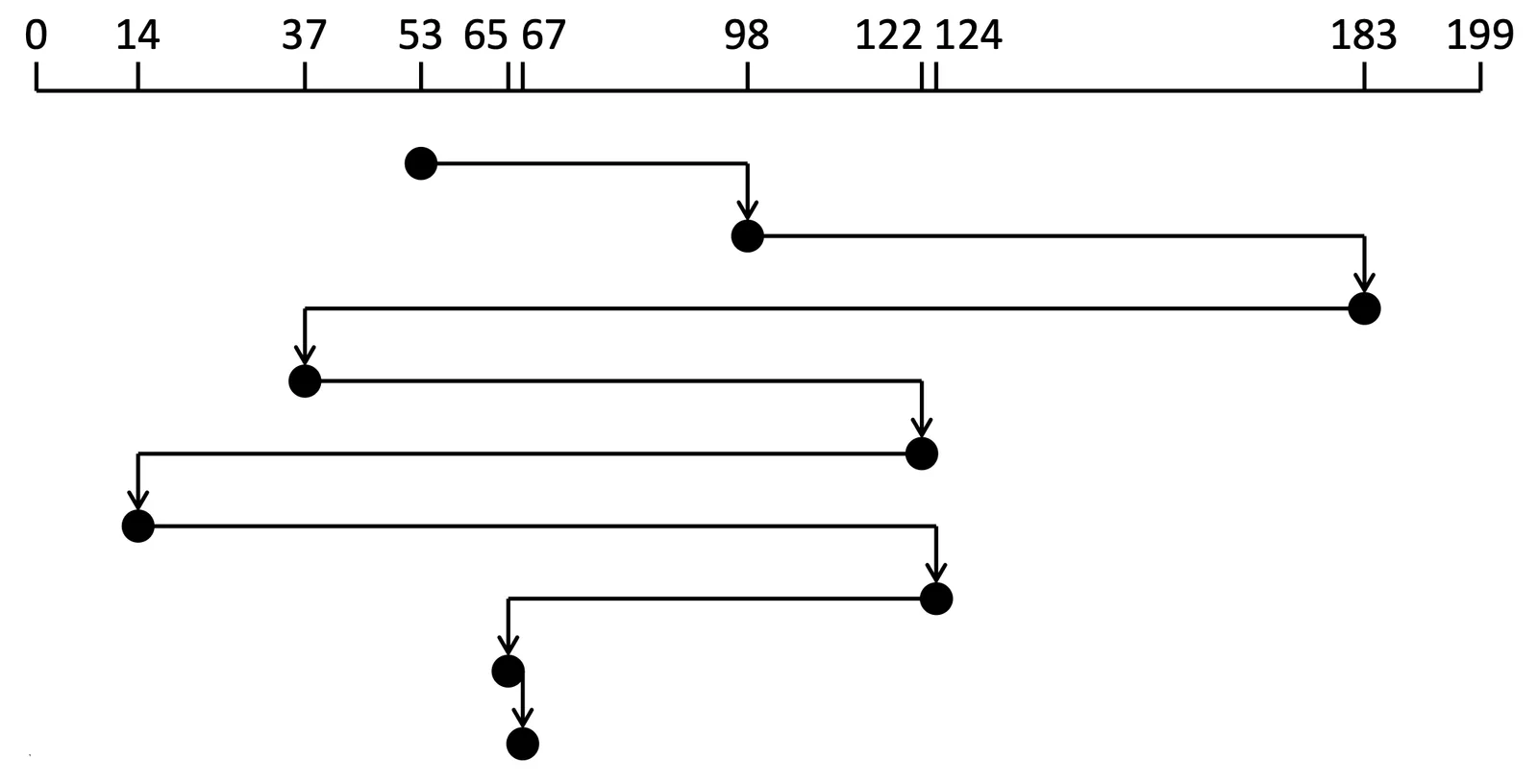
Example of FCFS
總共有 640 個 cylinders movement
SCAN Scheduling#
這種演算法會先從 end point 挪到另一個 end point,不停在兩端挪動,遇到誰就先處理誰,SCAN algorithm 也叫做 elevator algorithm
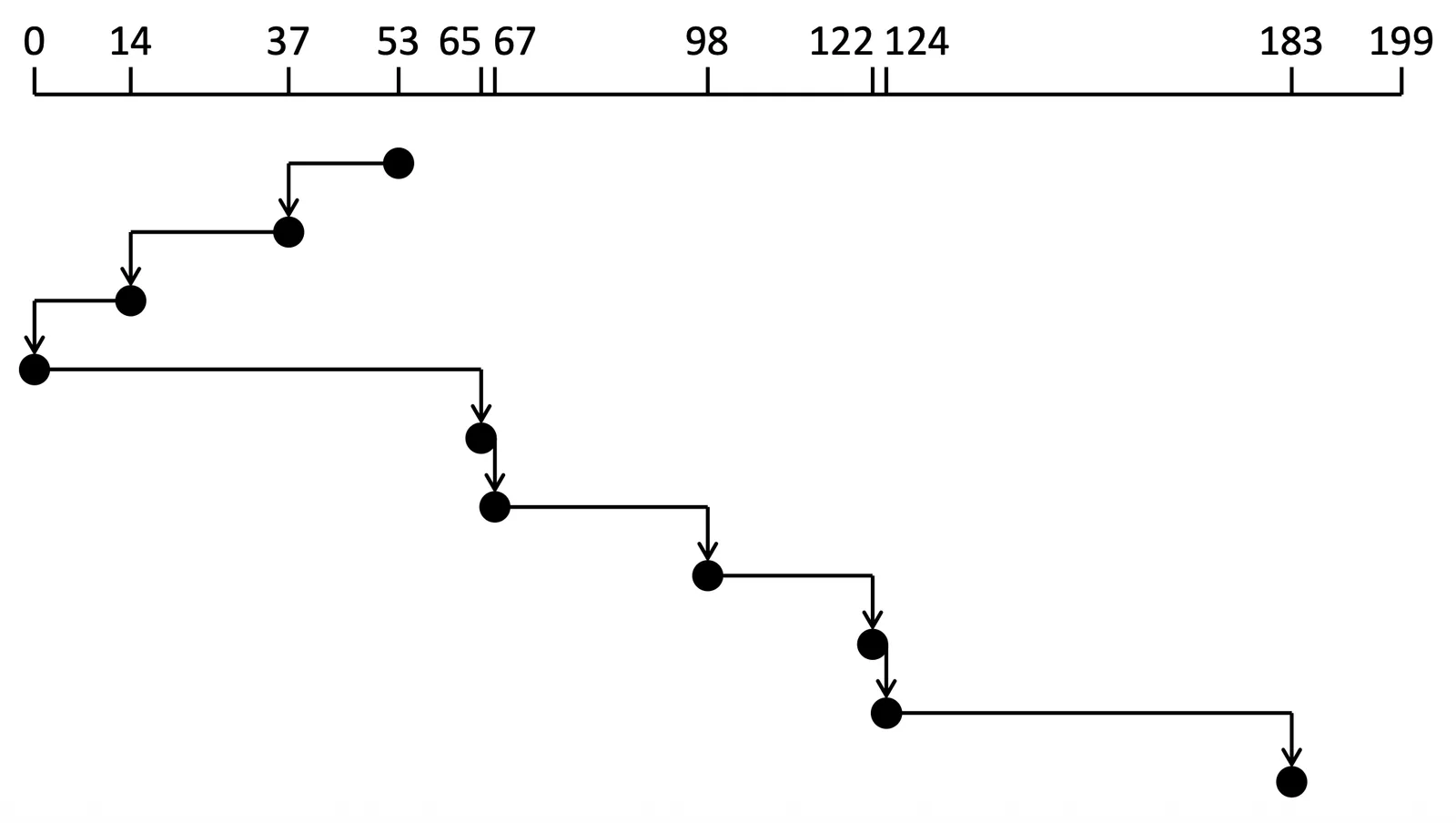
Example of SCAN
總共有 236 個 cylinders movement
假設從 A end 走到 B end,那當 head 走到 B end,A end 的 request density 就會太高,也就是說越靠近 A end 的 request 的 waiting time 會太長,我們需要改善
C-SCAN Scheduling#
把 SCAN 到末尾的操作改成 跳回原本的起始點,相較於 SCAN 會更加 Uniform
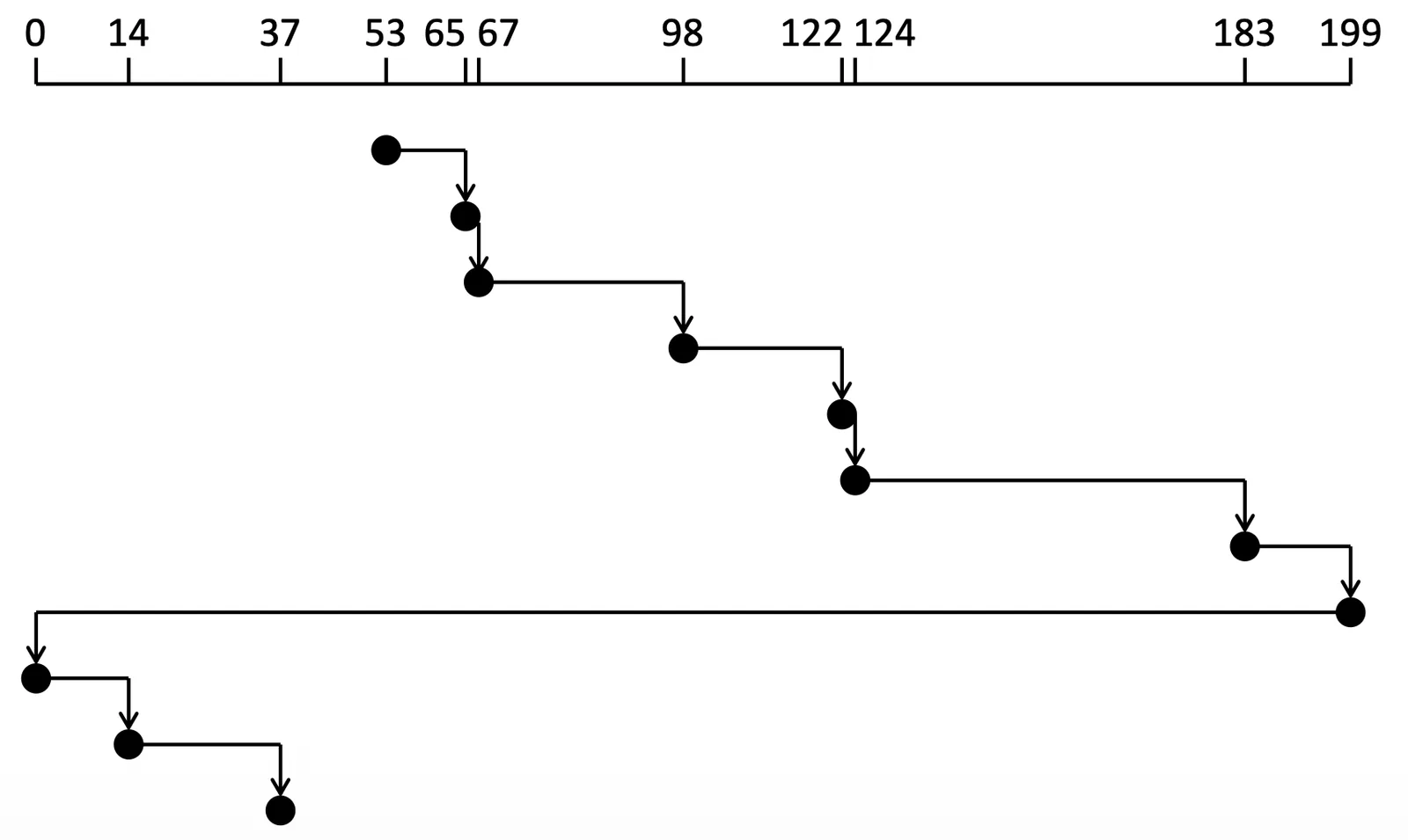
Example of C-SCAN
移動了 個 cylinders movement
Selecting a Disk-Scheduling Algorithm#
SCAN, C-SCAN 通常就有很不錯的效果了,在 Linux 裡面還提供 Deadline Scheduler,也就是分成
- Read Queue
- Write Queue
通常 Read Queue 的 Priority 會比較高,因為 read block 是比較常發生的,真正 implement 其實有四個 Queue:Read Queue, Write Queue 還會按照
- LBA order
- FCFS order
做排序,因為我們需要考慮到他的 arriving time,假設一個 request 存在的時間已經超過了設定的 deadline(500 ms default),那我們就會從 LBA Order 的 queue 裡面找到對應的 Block 裡面的所有 sector 做存取
其實還有各式各樣的 Scheduler(e.g. NOOP, completely fair queueing scheduler (CFQ))
NVM Scheduling#
NVM 沒有 head movement 的問題,因此直接使用 FCFS 其實就是很好的方法了,當然還是可以做一些修改
- Linux 的 NOOP 會把 LBA 靠近的 request merge 在一起
通常我們可以把 I/O 分成 Sequential 和 Random-access I/O,Random-access I/O 非常適合 NVM
- 用 IOPS (input/output operations per second) 做 metric
- HDD: IOPS
- SSD: IOPS
但 sequential 來講還是 HDD 適合
但在使用 NVM 的時候要注意 write amplification,也就是一個 write 因為 garbage collection 的關係,可能 trigger 好多個 I/O operation
Error Detection and Correction#
Error detection 就是要找錯誤,或是說發現錯誤,常用在 Networking
- Checksum: 上面就是一個例子,但在現代,我們通常使用 modular arithmetic 的 properties 去做應用
- Cyclic redundancy check (CRC):在 Network 常用,用 hash function 去做檢查
- Error-correction code (ECC):不只做通知,還會幫忙修正,但就需要更多 information
- soft error is recoverable
- hard error is signaled but noncorrectable
Storage Device Management#
Drive Formatting, Partitions, and Volumes#
在一個 disk 出場的時候其實就已經做好 Low-level formatting (or physical formatting),也就是把 sector 就設定好了
- Header
- Data
- Trailer (e.g., Error correction code)
但我們可以選擇 sector sizes,但當 OS 真正要使用前還要經過下面的步驟
- Partition: 要對硬碟做切割,決定哪一塊是 swap 哪裡是 OS 要的,哪裡是 User 的
- Mounting 就是讓 file system 變得可以讓 system, user 使用
- Volume: 做管理(C, D 槽)
- Logical formatting: 設定 initial 的 data structure
大部分的 file system 都會把 blocks group 成一個 cluster,因為 HDD 希望 data 是 sequential 的,所以會需要把 block 聚集,顯示他的 locality
Boot Block#
用來做 bootstrap 用的一塊空間,在 bootstrap 的時候會把他從 disk 上 load 進到 memory,存有這塊 Boot block 的 disk 就叫做 boot disk or system disk
拿 Windows 當例子,有一個 Master boot record (MBR)
- NVM 或 HDD 的第一個 block
- 裡面有一個 table 會存入 partition 的各種資訊,比如指向 boot program 的 partition
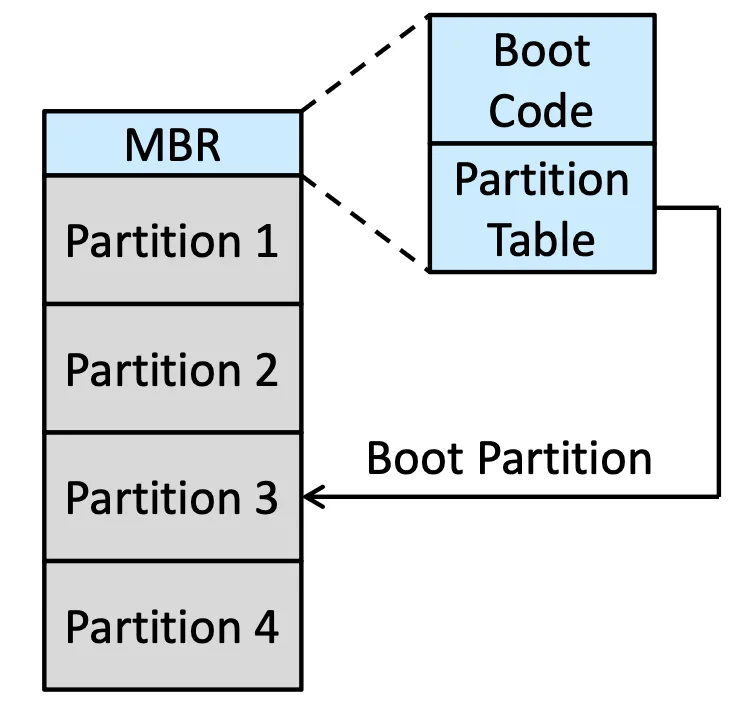
A Master Boot Record (MBR)
- Run the code in the system’s firmware
- Direct to read the boot code from the MBR
- Read the first sector/page from the boot partition which directs to the kernel
Bad Blocks#
一個 disk 出場一定會有一些 bad block,我們可以用 Sector sparing 來處理
- OS 想讀取 87-th sector
- Controller 計算 error-correction code (ECC) 發現這個 sector 是壞的
- Controller 回報 I/O error 給 OS
- Device controller 把 bad sector 取代成 spare
- 未來 OS 想讀 87 sector 的時候,controller 就會直接把它 translate 成 spare sector
或是我們做 Sector slipping 也就是平移
Swap-Space Management#
Swap out 跟 page out 可能會混用,但 swap 是整個 process 的 memory,這裡的 Swap-Space Management 是可以用在 swapping 也可以用在 paging 的空間
當 DRAM 空間不夠我們就要搬東西到 Swap space 上,所以我們需要 OS 來管理這件事,可以放在
- Raw partition
- File system 的一個 file
Linux 有一個 swap map,值是多少就代表有多少 process reference 到這裡(因為有 share memory 所以會超過 1)是 0 就表示這個 partition 可以使用
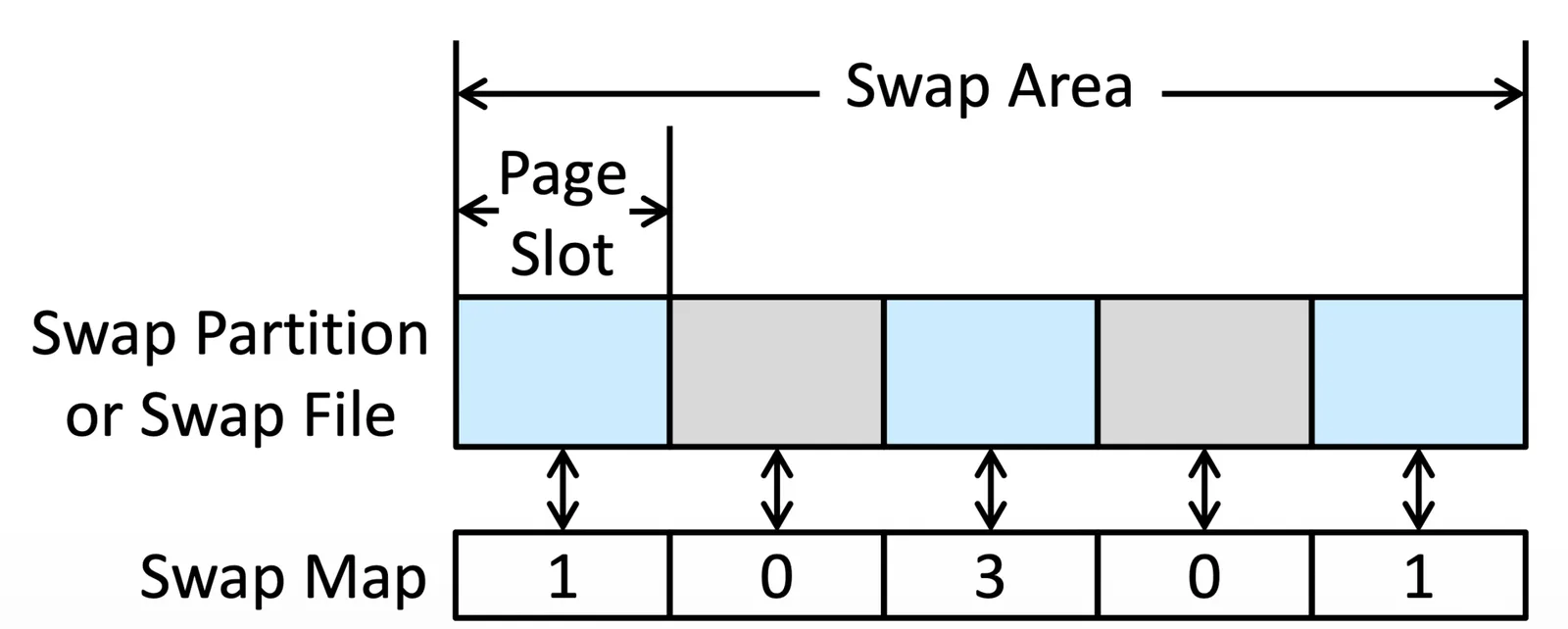
Linux Swapping Partition and Swap map
Storage Attachment#
Storage 到底是怎麼接上來的
Host-Attached Storage#
Host-attached storage 就是直接接在主機上用 local I/O port 讀寫的 storage,最常見的是 SATA,經典的 system 有多個 SATA port
想要更多空間也可以用 USB FireWire, Thunderbolt ports
如果是 server 等級的 machine 通常會用 fibre channel (FC) 當作 attachment
Network-Attached Storage (NAS)#
Network-attached storage (NAS) 是一種在網路上的 Storage,我們透過 remote-procedure-call (RPC) interface,可以用 TCP/UDP + IP 去做連接
這些伺服器不一定真的是一台 server,有可能只是一個 storage system 而已
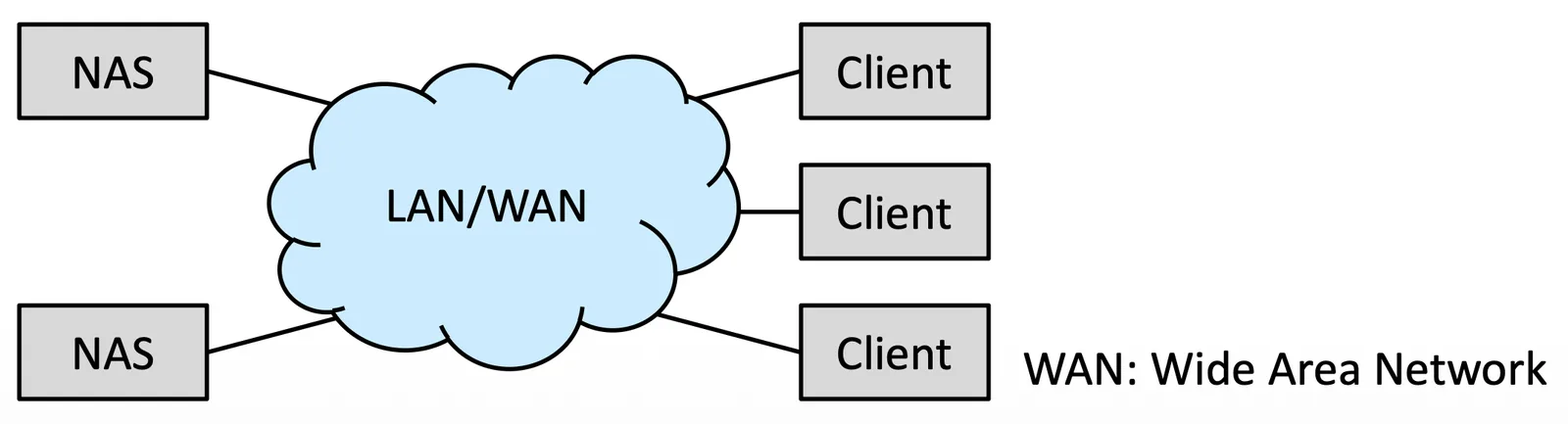
Example of NAS
有一些更進階的 protocol 像是 iSCSI,是一種用 IP 傳輸的 SCSI protocol,可以讓網路硬碟運作得像本地端一樣
Cloud Storage#
跟 NAS 不同的是,NAS 只是一個新的 File System,而 Cloud Storage 會連接到同一個 data center,採用 api-base 來連接 server,像是 google drive, dropbox,透過網頁、API、專用軟體就可以連接
Storage Area Networks (SAN) and Storage Arrays#
Storage Area Networks 就是一個 connect 很多 servers and storage units 的系統,非常彈性,可以隨意組合,有 multiple host 跟 multiple storage array,assign 的方法完全 dynamic
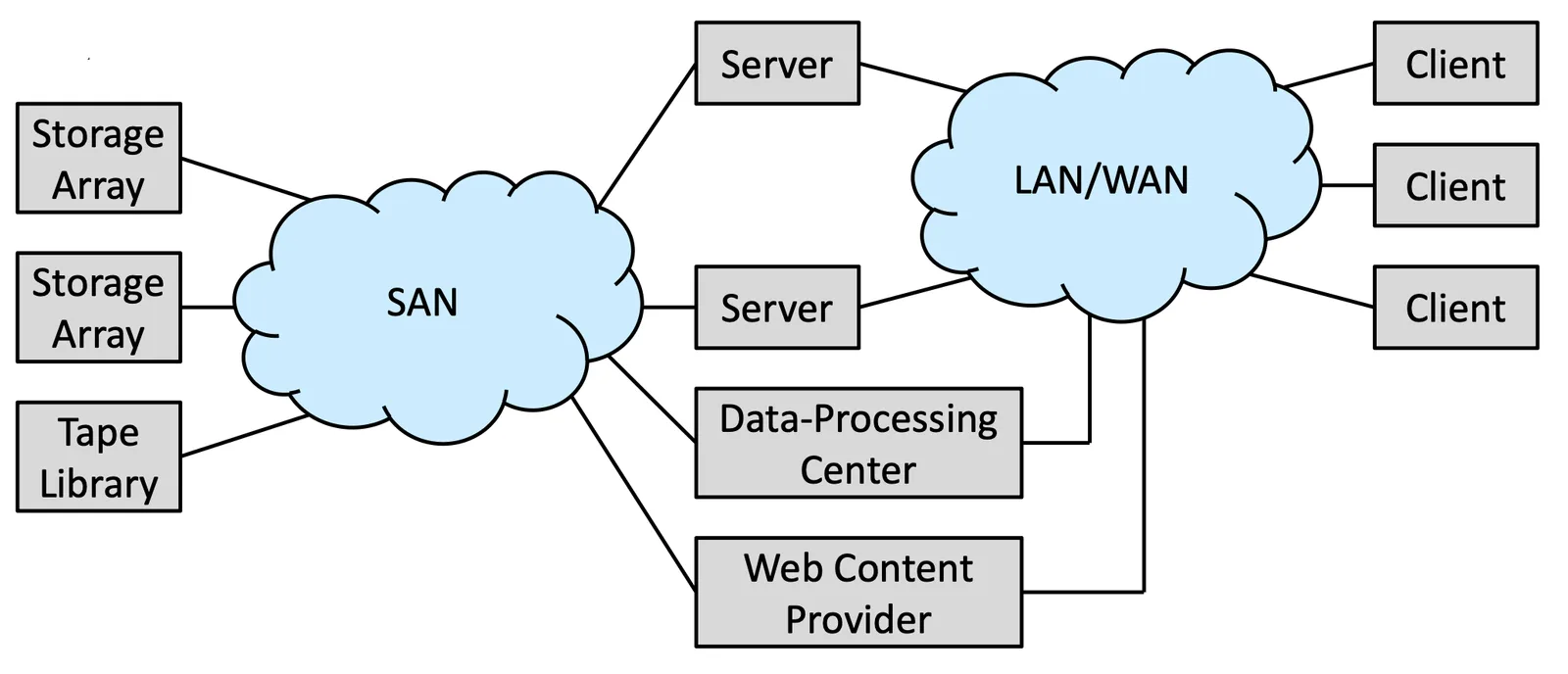
Storage Area Networks and Storage Arrays
storage array 可以根據我們希望的目的來打造,可以跟 Network 比較有關也可以跟 storage 有關
通常會用 FC 當作 Connection 或是 InfiniBand
RAID Structure#
Reliability via Redundancy#
全稱是 Redundant arrays of independent (inexpensive) disks (RAID),概念很簡單,就是要有備份,也就是用 redundancy 提升 reliability
計算 mean time to data loss 我們需要
- Mean time between failures (MTBF) 平均 loss 時間
- Mean time to repair 平均修復時間
現實生活中兩次 failure 不一定會 independent
Performance via Parallelism#
備份後,我們做 Parallelism 就會更方便,有一種方法叫 Data striping 假設我們把不同 bit 放在不同 drive 上,我們就可以讓每個 bit 做到 Parallelism,這樣子叫做 bit-level striping,當然也有 block-level striping
- Throughput of multiple small accesses 會增加
- Response time of large accesses 也會減少
RAID Levels#
- Mirroring 或是 shadowing 我們稱為 RAID 1 會 keep duplication
- Block interleaved parity (RAID 4, 5, 6) 就是比較少的 redundancy
- Striped mirrors (RAID 1+0) 或 mirrored stripes (RAID 0+1) 就是可以增加 performance 以及 reliability
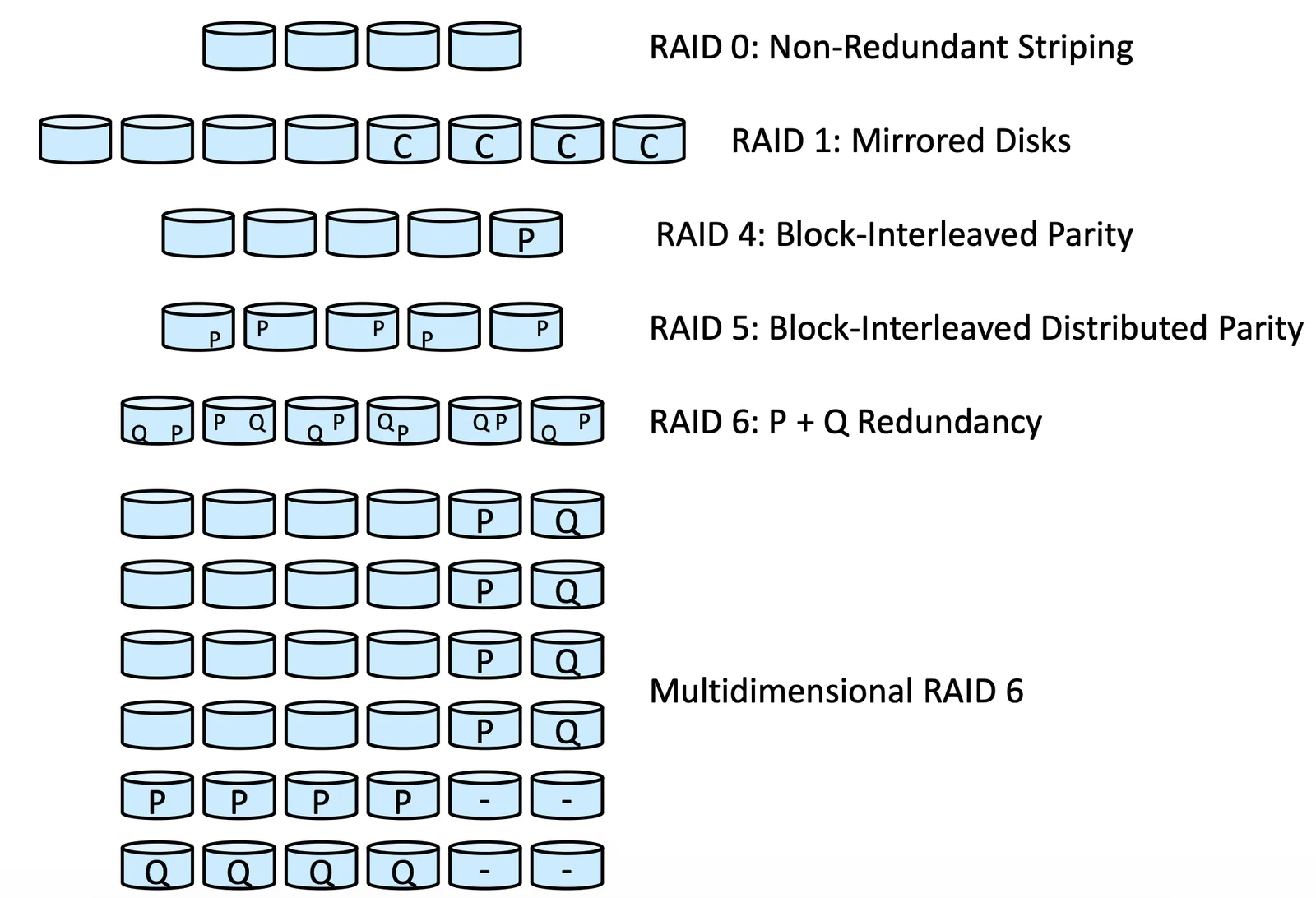
Illustration of RAID
- RAID 0:Non-Redundant
- RAID 1:Mirrored
- RAID 4:只用一個額外的 DISK 去存 parity
- RAID 5:parity 散布在多個 DISK 上
- RAID 6:parity 加上其他資訊,散布在多個 DISK 上
- Multidimensional RAID 6:用專門的 DISK 儲存 P 跟其他資訊
RAID 4, 5, 6 還是可以做到 error correction,Driver 會有一些 Failure information 但還是有機會可以修復
RAID 0+1,如果其中一個 Disk 壞掉,那整個 Stripe 都不能用了,但如果是 RAID 1+0 可以從 Mirror 的 DISK 去組合出來
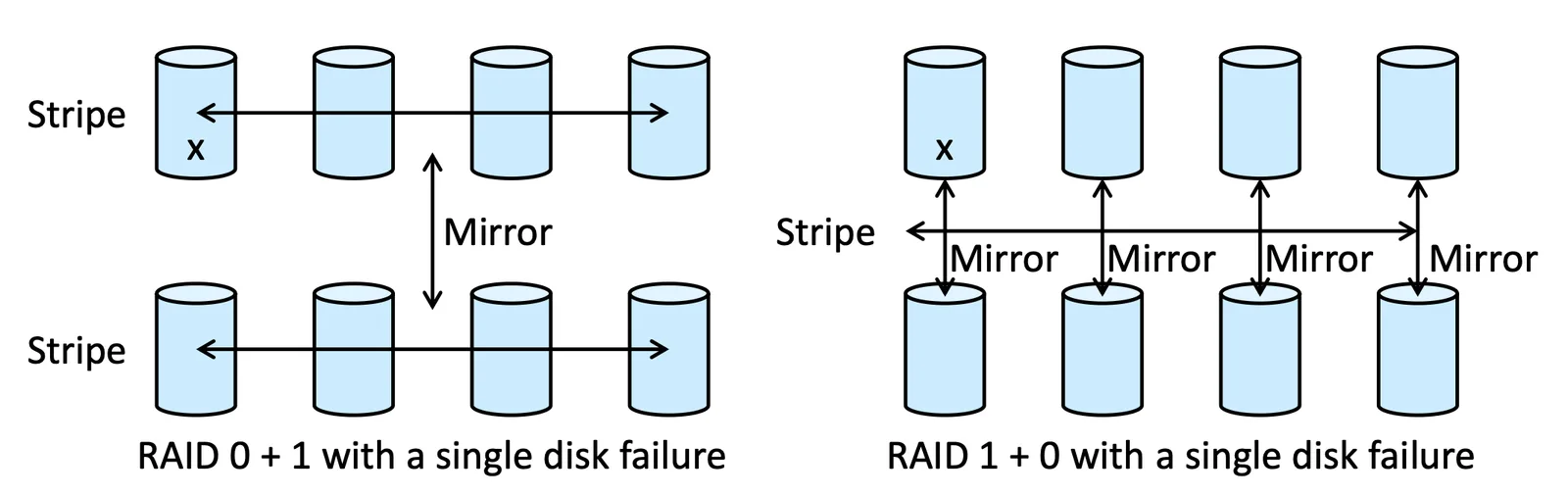
Illustration of RAID 0+1, RAID 1+0
- Snapshot:會在更新前做一個備份,可以 trace 發生啥事
- Replication:為了怕資料不見,我們想做到 automatically duplication write,這個方法可以 sync 也可以 async,通常還能達到 Fault Tolerance, Read Scalability